Summary
I wrote two versions of a program which computes the BLAKE3 hash of a file (source code here), a single-threaded version in C and a multi-threaded version in C++, both of which use io_uring. The single-threaded version is around 25% faster than the official Rust b3sum on my system and is slightly faster than cat to /dev/null on my system, and is also slightly faster than fio on my system, which I used to measure the sequential read speed of a system (see Additional Notes for the parameters that I used passed to fio and other details). The single-threaded version is able to hash a 10GiB file in 2.899s, which works out to around 3533MiB/s, which is roughly the same as the read speed advertised for my NVME drive (“3500MB/s”), which leads me to believe that it is the fastest possible file hashing program on my system and cannot be any faster because a file hashing program cannot finish hashing a file before it has finished reading the last block of the file from the disk. My multi-threaded implementation is around 1% slower than my single-threaded implementation.
I provide informal proofs that both versions of my program are correct (i.e. will always return the correct result) and will never get stuck (i.e. will eventually finish). The informal proofs are provided along with an explanation of the code in the The Code Explained section of this article.
My program is extremely simple, generic, and can be easily modified to do what you want, as long as what you want is to read from a file a few blocks at a time and process these blocks while waiting for the next blocks to arrive - I think this is an extremely common use case, so I made sure that it is trivially easy to adapt my program for your needs - if you want to do something different with each block of the file, all you need to do is to replace the call to the hashing function with a call to your own data processing function.
Benchmarks
For these tests, I used the same 1 GiB (or 10 GiB) input file and always flushed the page cache before each test, thus ensuring that the programs are always reading from disk. Each command was run 10 times and I used the “real” result from time to calculate the statistics. I ran these commands on a Debian 12 system (uname -r returns “6.1.0-9-amd64”) using ext4 without disk encryption and without LVM.
| Command | Min | Median | Max |
|---|---|---|---|
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 1 |
0.404s | 0.4105s | 0.416s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 2 |
0.474s | 0.4755s | 0.481s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 3 |
0.44s | 0.4415s | 0.451s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 4 |
0.443s | 0.4475s | 0.452s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 5 |
0.454s | 0.4585s | 0.462s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 6 |
0.456s | 0.4605s | 0.463s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 7 |
0.461s | 0.4635s | 0.468s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --num-threads 8 |
0.461s | 0.464s | 0.47s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time b3sum 1GB.txt --no-mmap |
0.381s | 0.386s | 0.394s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./b3sum_linux 1GB.txt --no-mmap |
0.379s | 0.39s | 0.404s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time cat 1GB.txt | ./example |
0.364s | 0.3745s | 0.381s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time cat 1GB.txt > /dev/null |
0.302s | 0.302s | 0.303s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K | ./example |
0.338s | 0.341s | 0.348s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K of=/dev/null |
0.303s | 0.306s | 0.308s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M | ./example |
0.538s | 0.5415s | 0.544s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M of=/dev/null |
0.302s | 0.303s | 0.304s |
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting |
0.302s | 0.3025s | 0.303s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_singlethread 1GB.txt 512 2 1 0 2 0 0 |
0.301s | 0.301s | 0.302s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_multithread 1GB.txt 512 2 1 0 2 0 0 |
0.303s | 0.304s | 0.305s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_singlethread 1GB.txt 128 20 0 0 8 0 0 |
0.375s | 0.378s | 0.384s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_multithread 1GB.txt 128 20 0 0 8 0 0 |
0.304s | 0.305s | 0.307s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time xxhsum 1GB.txt |
0.318s | 0.3205s | 0.325s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time cat 10GB.txt > /dev/null |
2.903s | 2.904s | 2.908s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_singlethread 10GB.txt 512 4 1 0 4 0 0 |
2.898s | 2.899s | 2.903s |
In the table above, liburing_b3sum_singlethread and liburing_b3sum_multithread are my own io_uring-based implementations of b3sum (more details below), and I verified that my b3sum implementations always produced the same BLAKE3 hash output as the official b3sum implementation. The 1GB.txt file was generated using this command:
dd if=/dev/urandom of=1GB.txt bs=1G count=1
I installed b3sum using this command:
cargo install b3sum
$ b3sum --version b3sum 1.4.1
I downloaded the b3sum_linux program from the BLAKE3 Github Releases page (it was the latest Linux binary):
$ ./b3sum_linux --version b3sum 1.4.1
I compiled the example program from the example.c file in the BLAKE3 C repository as per the instructions in the BLAKE3 C repository:
gcc -O3 -o example example.c blake3.c blake3_dispatch.c blake3_portable.c \ blake3_sse2_x86-64_unix.S blake3_sse41_x86-64_unix.S blake3_avx2_x86-64_unix.S \ blake3_avx512_x86-64_unix.S
I installed xxhsum using this command:
apt install xxhash
$ xxhsum --version
xxhsum 0.8.1 by Yann Collet
compiled as 64-bit x86_64 autoVec little endian with GCC 11.2.0`
The Short Story
As you can see from the results above, my single-threaded implementation is slightly faster than my multi-threaded implementation.
If the single-threaded version is faster, then why did I mention the multi-threaded version? Because, as the table above shows, the single-threaded version needs O_DIRECT in order to be fast (the flag that controls whether or not to use O_DIRECT is the third number after the filename in the command line arguments). The multi-threaded version is fast even without O_DIRECT (as the table shows, the multi-threaded version will hash a 1GiB file in 0.304s with O_DIRECT and 0.305s without O_DIRECT). Why would anyone care about whether or not a program uses O_DIRECT? Because the O_DIRECT version will not put the file into the page cache (it doesn’t evict the file from the page cache either - it just bypasses the page cache altogether). This is good for the use case where you just want to process (e.g. hash) a large number of large files as fast as possible, accessing each file exactly once each, for example if you want to generate a list of hashes of every file on your system. It is not so good for the use case where you have only one file and you want to hash it with this program and then another program (e.g. xxhsum) immediately afterwards. That’s why I mentioned the multi-threaded version of my program - it is fast even when not using O_DIRECT, unlike the single-threaded version.
One major caveat is that my program currently uses the C version of the BLAKE3 library. BLAKE3 has two versions - a Rust version and a C version, and only the Rust version supports multithreading - the C version currently does not support multithreading:
Unlike the Rust implementation, the C implementation doesn’t currently support multithreading. A future version of this library could add support by taking an optional dependency on OpenMP or similar. Alternatively, we could expose a lower-level API to allow callers to implement concurrency themselves. The former would be more convenient and less error-prone, but the latter would give callers the maximum possible amount of control. The best choice here depends on the specific use case, so if you have a use case for multithreaded hashing in C, please file a GitHub issue and let us know.
Multithreading could be beneficial when your IO speed is faster than your single-core hashing speed. For example, if you have a fast NVME, for example let’s say your NVME can do 7GB/s read but your CPU can only compute a BLAKE3 hash at say 4GB/s on a single core, then you might benefit from multithreading which enables you to have multiple CPU cores hashing the file at the same time. So the most obvious next step would be add io_uring support to the Rust b3sum implementation so that Linux systems can benefit from the faster IO. An alternative would be to add multithreading support to the C BLAKE3 implementation.
(Actually, having said that, I’m not sure if multithreading would always be faster. On most storage devices, sequential read is significantly faster than random read, and it looks like the current multithreaded Rust implementation does reads all over the file rather than reading the file in sequentially. So I think it’s possible that, in some situations, doing random reads might slow down IO so much that it will actually be slower than just sequentially reading in the file and doing hashing on a single core. But, obviously this depends on the hardware that you have. The ideal would be multi-core hashing with sequential read, but I’m not sure if the BLAKE3 algorithm actually allows that. If not, I guess you could just hash each chunk of the file separately, obtaining a list of hashes, then you could just store that list or you could store a hash of that list if you want to save space. That actually was my original plan before I discovered that BLAKE3 on a single core was faster than file read on my system.)
So yeah, I’m pretty sure my program runs at the theoretical speed limit of my system i.e. it is literally the fastest possible file hashing program on my system i.e. there is no further room for optimization - this one fact pleased me more than anything else. I wrote this article because I wanted to do a writeup explaining my program, and how I got my program to this point and actually I think it’s pretty surprising that nobody else (as far as I know) has used io_uring for a file hashing program yet - it’s such a perfect use case for io_uring, it’s pretty much the lowest-hanging fruit that I can think of.
Another caveat is that io_uring is Linux only, so this program cannot run on other operating systems.
The Code Explained
I will first explain the single-threaded version then explain the multi-threaded version.
So, here is the single-threaded version:
/* SPDX-License-Identifier: MIT */
/*
* Compile with: gcc -Wall -O3 -D_GNU_SOURCE liburing_b3sum_singlethread.c -luring libblake3.a -o liburing_b3sum_singlethread
* For an explanation of how this code works, see my article/blog post: https://1f604.com/b3sum
*
* This program is a modified version of the liburing cp program from Shuveb Hussain's io_uring tutorial.
* Original source code here: https://github.com/axboe/liburing/blob/master/examples/io_uring-cp.c
* The modifications were made by 1f604.
*
* The official io_uring documentation can be seen here:
* - https://kernel.dk/io_uring.pdf
* - https://kernel-recipes.org/en/2022/wp-content/uploads/2022/06/axboe-kr2022-1.pdf
*
* Acronyms: SQ = submission queue, SQE = submission queue entry, CQ = completion queue, CQE = completion queue event
*/
#include "blake3.h"
#include "liburing.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <assert.h>
#include <sys/ioctl.h>
/* Constants */
static const int ALIGNMENT = 4 * 1024; // Needed only because O_DIRECT requires aligned memory
/* ===============================================
* ========== Start of global variables ==========
* ===============================================
* Declared static because they are only supposed to be visible within this .c file.
*
* --- Command line options ---
* The following variables are set by the user from the command line.
*/
static int g_queuedepth; /* This variable is not really the queue depth, but is more accurately described as
* "the limit on the number of incomplete requests". Allow me to explain.
* io_uring allows you to have more requests in-flight than the size of your submission
* (and completion) queues. How is this possible? Well, when you call io_uring_submit,
* normally it will submit ALL of the requests in the submission queue, which means that
* when the call returns, your submission queue is now empty, even though the requests
* are still "in-flight" and haven't been completed yet!
* In earlier kernels, you could overflow the completion queue because of this.
* Thus it says in the official io_uring documentation (https://kernel.dk/io_uring.pdf):
* Since the sqe lifetime is only that of the actual submission of it, it's possible
* for the application to drive a higher pending request count than the SQ ring size
* would indicate. The application must take care not to do so, or it could risk
* overflowing the CQ ring.
* That is to say, the official documentation recommended that applications should ensure
* that the number of in-flight requests does not exceed the size of the submission queue.
* This g_queuedepth variable is therefore a limit on the total number of "incomplete"
* requests, which is the number of requests on the submission queue plus the number of
* requests that are still "in flight".
* See num_unfinished_requests for details on how this is implemented. */
static int g_use_o_direct; // whether to use O_DIRECT
static int g_process_in_inner_loop; // whether to process the data inside the inner loop
static int g_use_iosqe_io_drain; // whether to issue requests with the IOSQE_IO_DRAIN flag
static int g_use_iosqe_io_link; // whether to issue requests with the IOSQE_IO_LINK flag
//static int g_use_ioring_setup_iopoll; // when I enable IORING_SETUP_IOPOLL, on my current system,
// it turns my process into an unkillable zombie that uses 100% CPU that never terminates.
// when I was using encrypted LVM, it just gave me error: Operation not supported.
// I decided to not allow users to enable that option because I didn't want them
// to accidentally launch an unkillable never-ending zombie process that uses 100% CPU.
// I observed this behavior in fio too when I enabled --hipri on fio, it also turned into
// an unkillable never-ending zombie process that uses 100% CPU.
static size_t g_blocksize; // This is the size of each buffer in the ringbuf, in bytes.
// It is also the size of each read from the file.
static size_t g_numbufs; // This is the number of buffers in the ringbuf.
/* --- Non-command line argument global variables --- */
blake3_hasher g_hasher;
static int g_filedescriptor; // This is the file descriptor of the file we're hashing.
static size_t g_filesize; // This will be filled in by the function that gets the file size.
static size_t g_num_blocks_in_file; // The number of blocks in the file, where each block is g_blocksize bytes.
// This will be calculated by a ceiling division of filesize by blocksize.
static size_t g_size_of_last_block; // The size of the last block in the file. See calculate_numblocks_and_size_of_last_block.
static int producer_head = 0; // Position of the "producer head". see explanation in my article/blog post
static int consumer_head = 0; // Position of the "consumer head". see explanation in my article/blog post
enum ItemState { // describes the state of a cell in the ring buffer array ringbuf, see my article/blog post for detailed explanation
AVAILABLE_FOR_CONSUMPTION, // consumption and processing in the context of this program refers to hashing
ALREADY_CONSUMED,
REQUESTED_BUT_NOT_YET_COMPLETED,
};
struct my_custom_data { // This is the user_data associated with read requests, which are placed on the submission ring.
// In applications using io_uring, the user_data struct is generally used to identify which request a
// completion is for. In the context of this program, this structure is used both to identify which
// block of the file the read syscall had just read, as well as for the producer and consumer to
// communicate with each other, since it holds the cell state.
// This can be thought of as a "cell" in the ring buffer, since it holds the state of the cell as well
// as a pointer to the data (i.e. a block read from the file) that is "in" the cell.
// Note that according to the official io_uring documentation, the user_data struct only needs to be
// valid until the submit is done, not until completion. Basically, when you submit, the kernel makes
// a copy of user_data and returns it to you with the CQE (completion queue entry).
unsigned char* buf_addr; // Pointer to the buffer where the read syscall is to place the bytes from the file into.
size_t nbytes_expected; // The number of bytes we expect the read syscall to return. This can be smaller than the size of the buffer
// because the last block of the file can be smaller than the other blocks.
//size_t nbytes_to_request; // The number of bytes to request. This is always g_blocksize. I made this decision because O_DIRECT requires
// nbytes to be a multiple of filesystem block size, and it's simpler to always just request g_blocksize.
off_t offset_of_block_in_file; // The offset of the block in the file that we want the read syscall to place into the memory location
// pointed to by buf_addr.
enum ItemState state; // Describes whether the item is available to be hashed, already hashed, or requested but not yet available for hashing.
int ringbuf_index; // The slot in g_ringbuf where this "cell" belongs.
// I added this because once we submit a request on submission queue, we lose track of it.
// When we get back a completion, we need an identifier to know which request the completion is for.
// Alternatively, we could use something to map the buf_addr to the ringbuf_index, but this is just simpler.
};
struct my_custom_data* g_ringbuf; // This is a pointer to an array of my_custom_data structs. These my_custom_data structs can be thought of as the
// "cells" in the ring buffer (each struct contains the cell state), thus the array that this points to can be
// thought of as the "ring buffer" referred to in my article/blog post, so read that to understand how this is used.
// See the allocate_ringbuf function for details on how and where the memory for the ring buffer is allocated.
/* ===============================================
* =========== End of global variables ===========
* ===============================================*/
static int setup_io_uring_context(unsigned entries, struct io_uring *ring)
{
int rc;
int flags = 0;
rc = io_uring_queue_init(entries, ring, flags);
if (rc < 0) {
fprintf(stderr, "queue_init: %s\n", strerror(-rc));
return -1;
}
return 0;
}
static int get_file_size(int fd, size_t *size)
{
struct stat st;
if (fstat(fd, &st) < 0)
return -1;
if (S_ISREG(st.st_mode)) {
*size = st.st_size;
return 0;
} else if (S_ISBLK(st.st_mode)) {
unsigned long long bytes;
if (ioctl(fd, BLKGETSIZE64, &bytes) != 0)
return -1;
*size = bytes;
return 0;
}
return -1;
}
static void add_read_request_to_submission_queue(struct io_uring *ring, size_t expected_return_size, off_t fileoffset_to_request)
{
assert(fileoffset_to_request % g_blocksize == 0);
int block_number = fileoffset_to_request / g_blocksize; // the number of the block in the file
/* We do a modulo to map the file block number to the index in the ringbuf
e.g. if ring buf_addr has 4 slots, then
file block 0 -> ringbuf index 0
file block 1 -> ringbuf index 1
file block 2 -> ringbuf index 2
file block 3 -> ringbuf index 3
file block 4 -> ringbuf index 0
file block 5 -> ringbuf index 1
file block 6 -> ringbuf index 2
And so on.
*/
int ringbuf_idx = block_number % g_numbufs;
struct my_custom_data* my_data = &g_ringbuf[ringbuf_idx];
assert(my_data->ringbuf_index == ringbuf_idx); // The ringbuf_index of a my_custom_data struct should never change.
my_data->offset_of_block_in_file = fileoffset_to_request;
assert (my_data->buf_addr); // We don't need to change my_data->buf_addr since we set it to point into the backing buffer at the start of the program.
my_data->nbytes_expected = expected_return_size;
my_data->state = REQUESTED_BUT_NOT_YET_COMPLETED; /* At this point:
* 1. The producer is about to send it off in a request.
* 2. The consumer shouldn't be trying to read this buffer at this point.
* So it is okay to set the state to this here.
*/
struct io_uring_sqe* sqe = io_uring_get_sqe(ring);
if (!sqe) {
puts("ERROR: FAILED TO GET SQE");
exit(1);
}
io_uring_prep_read(sqe, g_filedescriptor, my_data->buf_addr, g_blocksize, fileoffset_to_request);
// io_uring_prep_read sets sqe->flags to 0, so we need to set the flags AFTER calling it.
if (g_use_iosqe_io_drain)
sqe->flags |= IOSQE_IO_DRAIN;
if (g_use_iosqe_io_link)
sqe->flags |= IOSQE_IO_LINK;
io_uring_sqe_set_data(sqe, my_data);
}
static void increment_buffer_index(int* head) // moves the producer or consumer head forward by one position
{
*head = (*head + 1) % g_numbufs; // wrap around when we reach the end of the ringbuf.
}
static void resume_consumer() // Conceptually, this resumes the consumer "thread".
{ // As this program is single-threaded, we can think of it as cooperative multitasking.
while (g_ringbuf[consumer_head].state == AVAILABLE_FOR_CONSUMPTION){
// Consume the item.
// The producer has already checked that nbytes_expected is the same as the amount of bytes actually returned.
// If the read syscall returned something different to nbytes_expected then the program would have terminated with an error message.
// Therefore it is okay to assume here that nbytes_expected is the same as the amount of actual data in the buffer.
blake3_hasher_update(&g_hasher, g_ringbuf[consumer_head].buf_addr, g_ringbuf[consumer_head].nbytes_expected);
// We have finished consuming the item, so mark it as consumed and move the consumer head to point to the next cell in the ringbuffer.
g_ringbuf[consumer_head].state = ALREADY_CONSUMED;
increment_buffer_index(&consumer_head);
}
}
static void producer_thread()
{
int rc;
unsigned long num_blocks_left_to_request = g_num_blocks_in_file;
unsigned long num_blocks_left_to_receive = g_num_blocks_in_file;
unsigned long num_unfinished_requests = 0;
/* A brief note on how the num_unfinished_requests variable is used:
* As mentioned earlier, in io_uring it is possible to have more requests in-flight than the
* size of the completion ring. In earlier kernels this could cause the completion queue to overflow.
* In later kernels there was an option added (IORING_FEAT_NODROP) which, when enabled, means that
* if a completion event occurs and the completion queue is full, then the kernel will internally
* store the event until the completion queue has room for more entries.
* Therefore, on newer kernels, it isn't necessary, strictly speaking, for the application to limit
* the number of in-flight requests. But, since it is almost certainly the case that an application
* can submit requests at a faster rate than the system is capable of servicing them, if we don't
* have some backpressure mechanism, then the application will just keep on submitting more and more
* requests, which will eventually lead to the system running out of memory.
* Setting a hard limit on the total number of in-flight requests serves as a backpressure mechanism
* to prevent the number of requests buffered in the kernel from growing without bound.
* The implementation is very simple: we increment num_unfinished_requests whenever a request is placed
* onto the submission queue, and decrement it whenever an entry is removed from the completion queue.
* Once num_unfinished_requests hits the limit that we set, then we cannot issue any more requests
* until we receive more completions, therefore the number of new completions that we receive is exactly
* equal to the number of new requests that we will place, thus ensuring that the number of in-flight
* requests can never exceed g_queuedepth.
*/
off_t next_file_offset_to_request = 0;
struct io_uring uring;
if (setup_io_uring_context(g_queuedepth, &uring)) {
puts("FAILED TO SET UP CONTEXT");
exit(1);
}
struct io_uring* ring = ů
while (num_blocks_left_to_receive) { // This loop consists of 3 steps:
// Step 1. Submit read requests.
// Step 2. Retrieve completions.
// Step 3. Run consumer.
/*
* Step 1: Make zero or more read requests until g_queuedepth limit is reached, or until the producer head reaches
* a cell that is not in the ALREADY_CONSUMED state (see my article/blog post for explanation).
*/
unsigned long num_unfinished_requests_prev = num_unfinished_requests; // The only purpose of this variable is to keep track of whether
// or not we added any new requests to the submission queue.
while (num_blocks_left_to_request) {
if (num_unfinished_requests >= g_queuedepth)
break;
if (g_ringbuf[producer_head].state != ALREADY_CONSUMED)
break;
/* expected_return_size is the number of bytes that we expect this read request to return.
* expected_return_size will be the block size until the last block of the file.
* when we get to the last block of the file, expected_return_size will be the size of the last
* block of the file, which is calculated in calculate_numblocks_and_size_of_last_block
*/
size_t expected_return_size = g_blocksize;
if (num_blocks_left_to_request == 1) // if we're at the last block of the file
expected_return_size = g_size_of_last_block;
add_read_request_to_submission_queue(ring, expected_return_size, next_file_offset_to_request);
next_file_offset_to_request += expected_return_size;
++num_unfinished_requests;
--num_blocks_left_to_request;
// We have added a request for the read syscall to write into the cell in the ringbuffer.
// The add_read_request_to_submission_queue has already marked it as REQUESTED_BUT_NOT_YET_COMPLETED,
// so now we just need to move the producer head to point to the next cell in the ringbuffer.
increment_buffer_index(&producer_head);
}
// If we added any read requests to the submission queue, then submit them.
if (num_unfinished_requests_prev != num_unfinished_requests) {
rc = io_uring_submit(ring);
if (rc < 0) {
fprintf(stderr, "io_uring_submit: %s\n", strerror(-rc));
exit(1);
}
}
/*
* Step 2: Remove all the items from the completion queue.
*/
bool first_iteration = 1; // On the first iteration of the loop, we wait for at least one cqe to be available,
// then remove one cqe.
// On each subsequent iteration, we try to remove one cqe without waiting.
// The loop terminates only when there are no more items left in the completion queue,
while (num_blocks_left_to_receive) { // Or when we've read in all of the blocks of the file.
struct io_uring_cqe *cqe;
if (first_iteration) { // On the first iteration we always wait until at least one cqe is available
rc = io_uring_wait_cqe(ring, &cqe); // This should always succeed and give us one cqe.
first_iteration = 0;
} else {
rc = io_uring_peek_cqe(ring, &cqe); // This will fail once there are no more items left in the completion queue.
if (rc == -EAGAIN) { // A return code of -EAGAIN means that there are no more items left in the completion queue.
break;
}
}
if (rc < 0) {
fprintf(stderr, "io_uring_peek_cqe: %s\n",
strerror(-rc));
exit(1);
}
assert(cqe);
// At this point we have a cqe, so let's see what our syscall returned.
struct my_custom_data *data = (struct my_custom_data*) io_uring_cqe_get_data(cqe);
// Check if the read syscall returned an error
if (cqe->res < 0) {
// we're not handling EAGAIN because it should never happen.
fprintf(stderr, "cqe failed: %s\n",
strerror(-cqe->res));
exit(1);
}
// Check if the read syscall returned an unexpected number of bytes.
if ((size_t)cqe->res != data->nbytes_expected) {
// We're not handling short reads because they should never happen on a disk-based filesystem.
if ((size_t)cqe->res < data->nbytes_expected) {
puts("panic: short read");
} else {
puts("panic: read returned more data than expected (wtf). Is the file changing while you're reading it??");
}
exit(1);
}
assert(data->offset_of_block_in_file % g_blocksize == 0);
// If we reach this point, then it means that there were no errors: the read syscall returned exactly what we expected.
// Since the read syscall returned, this means it has finished filling in the cell with ONE block of data from the file.
// This means that the cell can now be read by the consumer, so we need to update the cell state.
g_ringbuf[data->ringbuf_index].state = AVAILABLE_FOR_CONSUMPTION;
--num_blocks_left_to_receive; // We received ONE block of data from the file
io_uring_cqe_seen(ring, cqe); // mark the cqe as consumed, so that its slot can get reused
--num_unfinished_requests;
if (g_process_in_inner_loop)
resume_consumer();
}
/* Step 3: Run consumer. This might be thought of as handing over control to the consumer "thread". See my article/blog post. */
resume_consumer();
}
resume_consumer();
close(g_filedescriptor);
io_uring_queue_exit(ring);
// Finalize the hash. BLAKE3_OUT_LEN is the default output length, 32 bytes.
uint8_t output[BLAKE3_OUT_LEN];
blake3_hasher_finalize(&g_hasher, output, BLAKE3_OUT_LEN);
// Print the hash as hexadecimal.
printf("BLAKE3 hash: ");
for (size_t i = 0; i < BLAKE3_OUT_LEN; ++i) {
printf("%02x", output[i]);
}
printf("\n");
}
static void process_cmd_line_args(int argc, char* argv[])
{
if (argc != 9) {
printf("%s: infile g_blocksize g_queuedepth g_use_o_direct g_process_in_inner_loop g_numbufs g_use_iosqe_io_drain g_use_iosqe_io_link\n", argv[0]);
exit(1);
}
g_blocksize = atoi(argv[2]) * 1024; // The command line argument is in KiBs
g_queuedepth = atoi(argv[3]);
if (g_queuedepth > 32768)
puts("Warning: io_uring queue depth limit on Kernel 6.1.0 is 32768...");
g_use_o_direct = atoi(argv[4]);
g_process_in_inner_loop = atoi(argv[5]);
g_numbufs = atoi(argv[6]);
g_use_iosqe_io_drain = atoi(argv[7]);
g_use_iosqe_io_link = atoi(argv[8]);
}
static void open_and_get_size_of_file(const char* filename)
{
if (g_use_o_direct){
g_filedescriptor = open(filename, O_RDONLY | O_DIRECT);
puts("opening file with O_DIRECT");
} else {
g_filedescriptor = open(filename, O_RDONLY);
puts("opening file without O_DIRECT");
}
if (g_filedescriptor < 0) {
perror("open file");
exit(1);
}
if (get_file_size(g_filedescriptor, &g_filesize)){
puts("Failed getting file size");
exit(1);
}
}
static void calculate_numblocks_and_size_of_last_block()
{
// this is the mathematically correct way to do ceiling division
// (assumes no integer overflow)
g_num_blocks_in_file = (g_filesize + g_blocksize - 1) / g_blocksize;
// calculate the size of the last block of the file
if (g_filesize % g_blocksize == 0)
g_size_of_last_block = g_blocksize;
else
g_size_of_last_block = g_filesize % g_blocksize;
}
static void allocate_ringbuf()
{
// We only make 2 memory allocations in this entire program and they both happen in this function.
assert(g_blocksize % ALIGNMENT == 0);
// First, we allocate the entire underlying ring buffer (which is a contiguous block of memory
// containing all the actual buffers) in a single allocation.
// This is one big piece of memory which is used to hold the actual data from the file.
// The buf_addr field in the my_custom_data struct points to a buffer within this ring buffer.
unsigned char* ptr_to_underlying_ring_buffer;
// We need aligned memory, because O_DIRECT requires it.
if (posix_memalign((void**)&ptr_to_underlying_ring_buffer, ALIGNMENT, g_blocksize * g_numbufs)) {
puts("posix_memalign failed!");
exit(1);
}
// Second, we allocate an array containing all of the my_custom_data structs.
// This is not an array of pointers, but an array holding all of the actual structs.
// All the items are the same size, which makes this easy
g_ringbuf = (struct my_custom_data*) malloc(g_numbufs * sizeof(struct my_custom_data));
// We partially initialize all of the my_custom_data structs here.
// (The other fields are initialized in the add_read_request_to_submission_queue function)
off_t cur_offset = 0;
for (int i = 0; i < g_numbufs; ++i) {
g_ringbuf[i].buf_addr = ptr_to_underlying_ring_buffer + cur_offset; // This will never change during the runtime of this program.
cur_offset += g_blocksize;
// g_ringbuf[i].bufsize = g_blocksize; // all the buffers are the same size.
g_ringbuf[i].state = ALREADY_CONSUMED; // We need to set all cells to ALREADY_CONSUMED at the start. See my article/blog post for explanation.
g_ringbuf[i].ringbuf_index = i; // This will never change during the runtime of this program.
}
}
int main(int argc, char *argv[])
{
assert(sizeof(size_t) >= 8); // we want 64 bit size_t for files larger than 4GB...
process_cmd_line_args(argc, argv); // we need to first parse the command line arguments
open_and_get_size_of_file(argv[1]);
calculate_numblocks_and_size_of_last_block();
allocate_ringbuf();
// Initialize the hasher.
blake3_hasher_init(&g_hasher);
// Run the main loop
producer_thread();
}
How does it work?
Basically, my program reads a file from disk and then hashes it. In slightly more detail, my program issues read requests for blocks of the file, and then hashes the returned file blocks after they arrive. So, it is pretty much the simplest program imaginable that uses io_uring.
To really understand my program, the reader needs to know that io_uring is an asynchronous API which consists of two rings, a submission queue (SQ) and a completion queue (CQ). The way you use it is simple: you put your requests, which are called Submission Queue Entries (SQEs), into the SQ, then you call submit(), and then you poll or wait on the CQ for completions aka Completion Queue Events (CQEs). The important thing to remember about io_uring is that by default, requests submitted to io_uring may be completed in any order. There are two flags that you can use to force io_uring to complete the requests in order (IOSQE_IO_DRAIN and IOSQE_IO_LINK), but they greatly reduce the performance of the program, thus defeating the entire purpose of using io_uring in the first place (of course, this makes sense given how they work - these flags make it so that the next sqe won’t be started until the previous one is finished, which kind of almost defeats the entire point of having an asynchronous API…actually I found that the IOSQE_IO_LINK didn’t even work - I was still getting out of order completions - but it did slow down my program by a lot…that was on an earlier version of my program though) - you can actually easily check this for yourself: my program exposes those flags as command line parameters. I actually tried to use those flags to begin with, and only when I could not obtain acceptable performance while using the flags did I finally accept that I had to just deal with out-of-order completions. Actually, there are some use cases out there which do not need file blocks to be processed in order (such as file copying, for example). Unfortunately, file hashing is not one of those use cases - when hashing a file, we usually do need to process the blocks of the file in order (at least, the BLAKE3 C API doesn’t offer the option to hash blocks in arbitrary order). Therefore, we need some way to deal with out-of-order completions.
So, the simplest way to deal with this that I could think of was to just allocate one array big enough to hold the entire file in memory, then, whenever a completion arrives, we put it into the array at the appropriate slot in the array. For example, if we have a file that consists of 100 blocks, then we will allocate an array with 100 slots, and when we receive the completion for, say, the 5th block, then we will place that completion into the 5th slot in the array. This way, the file hashing function can simply iterate over this array, waiting for the next slot in the array to be filled with a completion before continuing. I actually made both a single-threaded as well as a multithreaded implementation of the approach described above, and they were actually very close to the fastest possible performance, but they did not reach the speed limit.
In order to reach the speed limit, I had to make one more optimization. And that optimization is to use a fixed-size ring buffer instead of allocating a single buffer that is big enough to hold all of the blocks of the file. Besides being faster, this also had the advantage of using less memory - that actually was the original reason I implemented it - I didn’t think that it would speed up my program, I only implemented it because my computer kept running out of memory when I was using the program to hash large files. So I was quite pleasantly surprised to discover that it actually improved the performance of my program.
Now, the ring buffer implementation is a little bit more complicated, so let’s think about the question: What is the correctness property for this algorithm? I thought of this:
The consumer will process all the blocks of the file exactly once each and in order.
It is actually trivial to write a consumer that will process the blocks of the file exactly once each and in order. The tricky part is making sure that it will process ALL of the blocks of the file. How do we ensure that it will process the blocks of the file exactly once each and in order? Simple: with the following implementation: the consumer simply iterates over the array and looks at the state and block offset of the next cell - if the state of the cell is “ready to be processed” and the block offset is that of the block that it wants, then the consumer will consume it. All the consumer needs to do is to internally keep track of the offset of the last block it has consumed, and add the block size to that offset to get the offset of the next block that it wants.
But there is another consideration that we must not forget - the queue depth. More precisely, as I explained in the code comments, it is essentially the number of requests that are in-flight. Why is this important? Because io_uring is an asynchronous API - the submit returns instantly, so you can just keep putting more and more requests in, submitting them, and (at least on some versions of the kernel) eventually the system will run out of memory. So we need to limit the number of requests that can be in-flight at any given moment, and the simplest way to do this is to use a counter - we decrement the counter whenever we issue a request and we increment the counter whenever we receive a completion. When the counter hits 0 we stop issuing new requests and just wait for completions. In this way we can ensure that the number of requests that are in-flight can never exceed the initial size of the counter.
With this design, we can’t issue requests for the entire file at a time. If the file consists of, say, 1 million blocks, we can’t just issue 1 million read requests at the start of the program and just poll for completions, since we can’t allow more than a small number of in-flight requests at any given moment. Instead, we have to limit ourselves to sending requests for a few blocks at a time, and waiting for at least one request to complete before sending any new requests.
Let’s give an example. Suppose we have a ring buffer that has 5 slots, and a queue depth limit of 3, meaning we can only have up to 3 in-flight requests at a time. At the beginning of the program, we can issue 3 requests. Now the question is which 3 do we want to issue for? The answer is quite obvious: the first 3 blocks (which corresponds to the first 3 slots), and we want to issue them in the order of block 0, then block 1, then block 2. Why? Because even though there is no guarantee that the requests will finish in the order that they were issued, the kernel will at least attempt those requests in the order that they were issued (since it is a ring buffer after all). And we want the first block to finish first, because that would allow the consumer to begin working as soon as possible - for the sake of efficiency, we want the consumer to always be processing some data, so we want the first block to return first (rather than, say, the second block to return first). So, taking this principle further, it means that we want to issue requests in the order that would unblock the consumer as soon as possible. That means that, if the consumer is currently waiting for block i to become “available for processing” then the producer must issue a request for block i before it issues a request for any other blocks. Reasoning forward, the producer should also issue the request for block i+1 before it issues the request for the block i+2, and it should issue the request for block i+2 before it issues a request for block i+3, and so on. Therefore, the producer should issue requests for blocks in the order 0, 1, 2, 3, … and so on until the last block.
So, we now have that the consumer has what is essentially a “consume head” that continually moves forward to the next cell in the ringbuffer whenever it can, but this is also the case for the “producer head” which I think is more accurately called the “requester head”. Thus, we have 2 pointers:
- A “consumer head” pointer which enables the consumer to linearly iterate through the ring buffer, processing slots one at a time, sequentially.
- A “requester head” pointer which enables the producer to linearly iterate through the ring buffer, issuing requests for slots one at a time, sequentially.
The “requester head” points to the slot for which the producer will issue the next read request - the read syscall will then fill in that slot with the block from the file. Once the producer has issued a request for a block, it should then issue a request for the next block, as I explained, unless it cannot. When can it not? There are 2 cases: Firstly, if the number of request in-flight has reached the limit, then it can no longer issue any new requests until we get a completion. Secondly, it cannot issue a request if the next slot is not available for it to issue a request on. It is important to remember that blocks are mapped to slots in the ring buffer, and that issuing a request for the next block in the file means that it needs the next slot in the ring buffer to be “free” i.e. can be used for being filled in. Now, if the consumer is currently reading that slot, then obviously it cannot issue a request for that slot. But there are also other situations where it cannot issue a request for that slot, for example, if it has already issued a request for that slot, but the consumer hasn’t read that slot yet. I think it’s easier to understand this with an example:
There are basically two cases. The first is when the queue depth is smaller than the number of slots in the ring buffer, and the second is when the queue depth is greater than the number of slots in the ring buffer. Let’s go through them in turn. See this diagram:
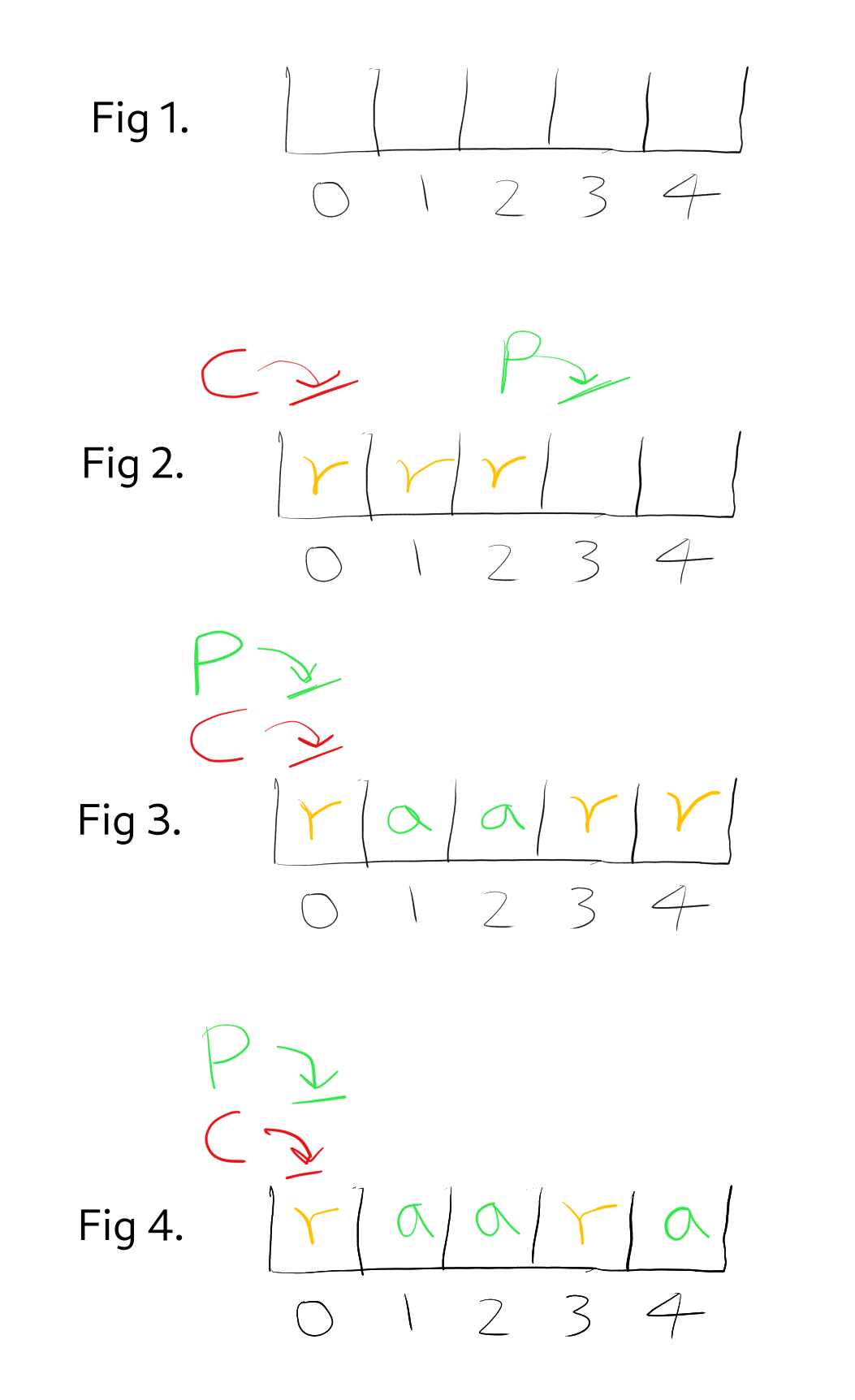
To begin with, suppose we set the queue depth to 3 and the ring buffer size to 5 slots. Initially (Fig 1.) the ring buffer is empty, so the consumer cannot move but the producer can start making requests, so it does. Since the queue depth is 3 that means the producer can make up to 3 requests to begin with. So now (Fig 2.) we have made 3 requests, one request each for blocks 0, 1, and 2, corresponding to slots 0, 1, and 2. Here I use the symbol “r” to represent slots for which we have made a read request, but the read request hasn’t yet returned. This means that the consumer cannot read them, since the slots don’t contain the data yet. Now, suppose the read requests for slots 1 and 2 return, but the read request for slot 0 still hasn’t returned (Fig 3.). This means that even though slots 1 and 2 are available for reading, the consumer cannot advance because it is still blocked waiting for slot 0 to become available for processing. But, since we have received completions for blocks 1 and 2, that means we can issue 2 more requests, so we issue requests for the next 2 blocks for which we haven’t yet issued requests, which are slots 3 and 4. Now (Fig 4.) suppose that the read call returns for slot 4, but slot 0 is still waiting. But now, the number of requests in flight is only 2, which means the producer is not prevented by the queue depth from issuing more read requests. However, the consumer is still blocked waiting for slot 0 to become available for consumption. At this point, would it be okay for the producer to overwrite it? Now, the producer wants to issue the read request for block 5, to be written into slot 0, but the consumer hasn’t seen block 0 yet, so clearly the producer should NOT make a request for slot 0 until the consumer has processed it. From this we can extrapolate a general principle. Earlier we mapped each slot to a list of blocks, e.g. if the ring buffer has 5 slots then we mapped slot 0 to block 0, block 5, block 10, block 15 and so on. And I hope the diagram has shown that we need to make sure to not request block 5 before the consumer is finished with block 0, because they both map to the same slot, meaning if we requested block 5 before the consumer is finished with block 0, then we would overwrite the slot where block 0 was going to be stored. More generally, by ensuring that we ONLY request the “next” block for each slot AFTER the consumer is finished with the “previous” block for that slot, we ensure that we don’t overwrite blocks that are being processed or haven’t been processed yet.
So that’s one way to look at it. Another way is to think in terms of the cell states. In the diagram we have shown 2 states that a cell could be in - the “r” state and the “a” state. Now, we can ask: what state must a cell be in in order for the producer to be allowed to make a request for that cell? Well, if the cell is in the “r” state, then that means that the producer has already made a request for that cell, and that the consumer hasn’t yet consumed that cell (obviously, because it’s not available for consumption yet), which means that if we overwrite that cell, that means we’re going to be overwriting a block for which we have already made a request. The case I’m talking about is when the producer moves to the next cell, and finds that that cell is in the “r” state - this can only mean one thing, which is that the producer has gone the full way around the ring buffer and is now looking at a cell which is waiting to receive the “previous” block for that slot compared to the one that the producer wants to request next, and we just explained that it would be an error to issue a request in this case. Actually, I think this way of looking at it - in terms of cell states - is easier to reason about. So, how many cell states are there? I can think of a few:
- Empty (at the start of the program)
- Requested but not yet completed
- Completed reading and available for processing
- Currently being processed
- Finished being processed
But do we really need to represent all of these states? Well, what are the states for in the end? They’re there to ensure the correctness of the program, which is:
- That the consumer does not consume incorrect blocks, and only consumes the correct blocks in the right order, and only once each
- That the consumer won’t get stuck
To ensure these correctness properties, all we need to do is to ensure the following:
- The consumer advances exactly when it’s okay to do so
- The producer advances exactly when it’s okay to do so
I used the word “exactly” to convey the two requirements: that the consumer/producer should not advance when it’s not safe to advance (correctness), and also that it must advance as soon as it is safe to do so (efficiency). Since that is the only purpose of having cell states, we can therefore boil the states down to just these 4:
- Available for consumer but not producer
- Available for producer but not consumer
- Available for both
- Available for neither
In fact, state 3 cannot exist, because we cannot have a cell being simultaneously accessed by both the consumer and the producer - that would be a data race (since the producer is writing to the cell while the consumer is reading it) and therefore undefined behavior. So really there can only be 3 states:
- Available for consumer but not producer (I shall refer to this as the “a” state - “available for processing”)
- Available for producer but not consumer (I shall refer to this as the “c” state - “already consumed”)
- Available for neither (I shall refer to this as the “r” state - “requested but not yet completed”)
We can then map the states that we have mentioned previously into those 3 states.
So, now we have the complete lifecycle for a cell in the ring buffer: At the start of the program, all the cells are empty, so the consumer cannot consume any of them but the producer can issue requests for them, so initially we need to mark every block in the array as in the “c” state so that the producer will issue requests for them but the consumer will not try to consume them. Once the producer has issued a request for that cell, then that cell will go into the “r” state until the read request completes. Why? Because as explained earlier, if the producer has issued a read request for a cell, but the read request hasn’t returned yet, then the producer should not overwrite that cell, and the consumer can’t process it either since it hasn’t been filled yet, so the “r” state is appropriate here. Next, the read request returns, so we change the cell to the “a” state. Why? Because after the read request returns for a cell, that cell can now be processed by the consumer, but we don’t want the producer to issue a request for that cell before the consumer is done with it, therefore the “a” state is appropriate here. While the consumer is processing the cell, the producer should not issue a request for it, so it is ok for the cell to remain in the “a” state. When the consumer is done with the cell, now the producer can issue a request for it, but the consumer should not attempt to consume the cell again (since it has already hashed the file block, passing it to the hash update function again would cause an incorrect result), therefore we must transition the cell to the “c” state. And finally, once the producer head reaches the cell again, the cycle begins anew.
But how does this design satisfy the correctness properties that we want the program to have? What we’d like is some kind of proof that the consumer won’t get stuck. So, suppose the consumer head is currently at slot i. What would stop it from moving to slot i+1? The only thing would be if the current slot is not in the “a” state - if it’s in the “a” state, then the consumer would process it and then move on to the next slot. So all we need to do is to show that if a slot is in a non-“a” state, that it will eventually transition into the “a” state. So how do we show that? Well there are only two non-“a” states: “r” and “c”. If a slot is in the “r” state, then it is just waiting for the read syscall to return, and so when that read syscall returns then the state will turn into “a”, so all “r” cells will turn into “a” eventually. If a slot is in the “c” state, then we need some guarantee that the producer will eventually turn it into the “r” state. This also is actually very easy to show - the producer will continually move across the array turning all "c"s into "r"s, only stopping if the number of requests in-flight has hit the limit, or if the producer has reached a cell that is not in the “c” state (note that here I’m talking about the conceptual high-level abstract design, rather than any specific implementation). The only thing we need to prove, then, is that the producer will never get blocked by a non-“c” cell from reaching a “c” cell. Well, it is probably easier to see it with a diagram:
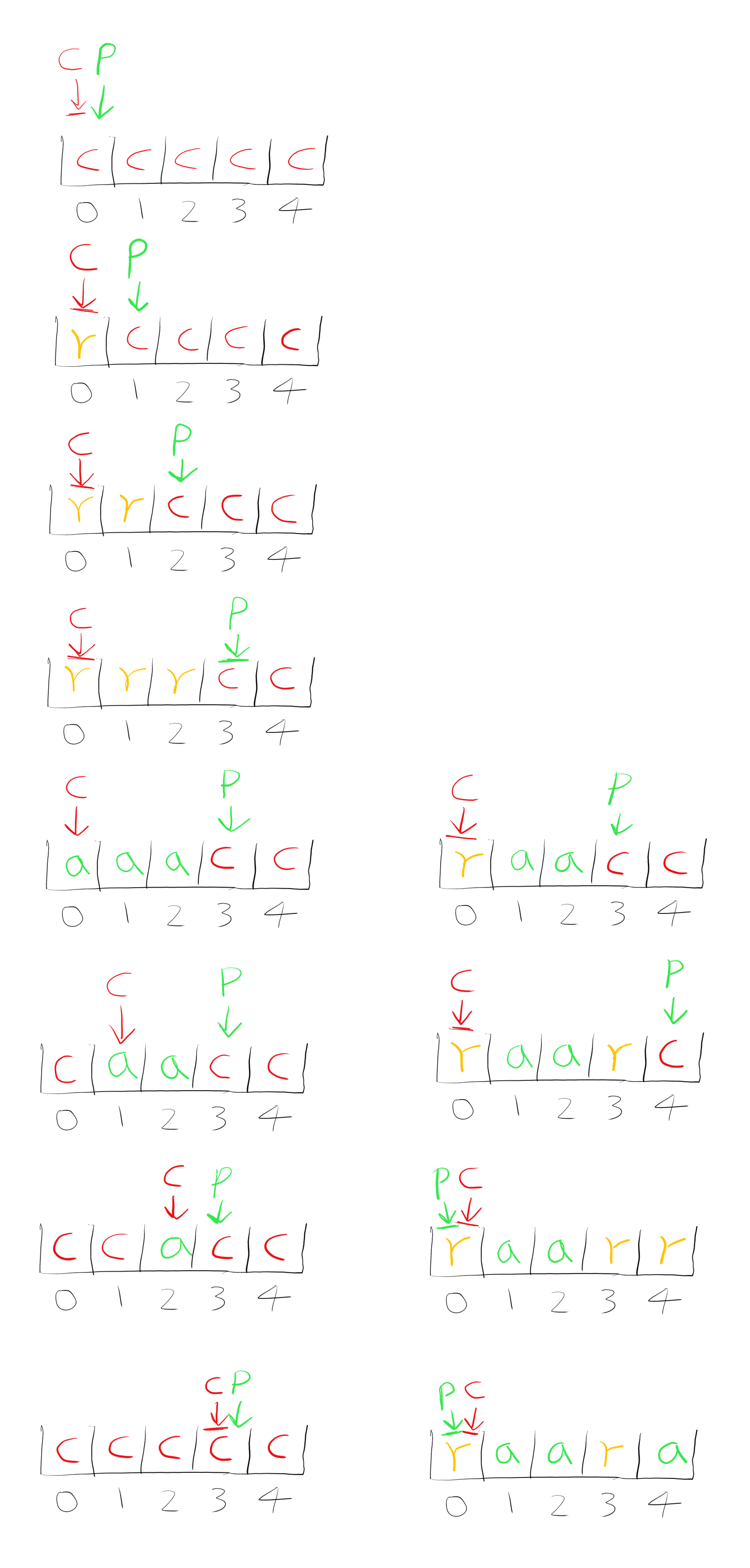
The above diagram shows a ring buffer of size 5 with a queue depth of 3 (the diagram shows what happens when the queue depth is smaller than the size of the ring buffer - it just means that the requester loop won’t issue more requests until more completions arrive. As you can see, as the producer head iterates through the ring buffer one slot at a time, each time requesting for the next block of the file, so the consumer follows the producer head, and so every time the consumer processes a new slot, that is the next block of the file. If the queue depth is greater than or equal to the size of the ring buffer, then the situation is simpler: the requester loop will just issue requests for every cell in the array that is in the “c” state). At the start, both the consumer and producer heads are pointing to the first slot, which is slot 0. Now, at this point, the consumer head is stuck and can’t move, but the producer head can move, so the producer head moves first - it submits the requests, and the producer head moves 3 slots over, until it hits the queue depth, then we check for completions. Now here is where different things can happen. On the left hand side is what would happen if all 3 requests returned right there and then. In that case, all the slots that were in the “r” state are now in the “a” state, so when we run the consumer, the consumer will happily iterate across all of those “a” slots, processing them as it goes along, turning them into “c” slots when it has finished processing them, and finally it will reach slot 3 which is still in the “c” state, so now the consumer stops and returns control back to the producer. In the alternative universe where the slot 0 remained in the “r” state, then the consumer would still be waiting for slot 0, and so hands control back to the producer, who will then proceed to issue requests for slots 3 and 4 since the number of in flight requests dropped below the queue depth. Then we ask for completions, and see that slot 4 has returned, so we transition it to “a”, and we try to run the consumer again but it is still waiting for slot 0, then we go back to the producer and it’s also waiting for slot 0.
So, I wanted to prove that there can never be a case where the producer will get permanently blocked, and that’s because, as the diagram shows, as the producer moves across the ring buffer it leaves behind a trail of cells in the “r” state which eventually transition into the “a” state. And similarly, as the consumer moves across the ring buffer it leaves behind a trail of cells in the “c” state. Therefore we have an assurance that the “c” cells and the “a”/“r” cells do not “mix” - all of the cells “behind” the consumer head but “in front” of the producer head are “c”, while all of the cells “behind” the producer head but “in front” of the consumer head are "r"s or "a"s. Therefore, as the diagram shows, when the producer head reaches a slot in the “r” or “a” state, then that means it has caught up to the consumer head, since if it was behind the consumer head then it would be seeing cells in the “c” state. Therefore, that means it is at the same cell where the consumer head is pointing to. If the cell is in the “a” state then the consumer will process it turning it into the “c” state, and if it’s in the “r” state then it will eventually turn into the “a” state, and then the consumer will process it turning it into the “c” state.
The reasoning above is for a generic multi-threaded implementation where the producer and consumer are on separate threads. But what about our single-threaded ring buffer implementation? Well, actually the sequence of events that I’ve shown above is consistent with the order of events in my single-threaded ringbuffer implementation, which consists of a main loop that consists of 3 sub-loops which are executed one after another - a “requester loop” which issues requests, a “completion loop” which checks for completions, and finally a “consumer loop” which runs the consumer. I want to show that this execution order can NEVER get stuck. So, to begin with, the requester loop may issue zero or more requests. As we discussed, it will issue requests until either the number of requests in flight reaches the queue depth, or until the producer head reaches a slot that is not in the “c” state. So this loop runs very fast and can never get stuck. Next, we wait until the completion queue contains at least one completion, and then we remove all of the completions from the completion queue. So, can this loop get stuck? That could only happen if we were waiting forever to see a completion. And that would only be possible if there are no cells in the “r” state. Why? Because if there is at least one cell that is in the “r” state, then the read syscall will eventually return and we will get a completion event. So, is it possible for there to be no cells in the “r” state when we wait on the completion queue?
Let’s think about the conditions required for that to happen:
- There are no requests in flight
- The requester loop didn’t issue any requests
So, what is the scenario where the requester loop didn’t issue any requests, but there are also no requests in flight? That is only possible if the cell that the producer head was pointing to was not in the “c” state. And since there are no cells in the “r” state, then that means the cell must be in the “a” state. I have previously explained that the only situation where this is possible is if the producer head has caught up to the consumer head (since the consumer leaves behind a trail of cells in the “c” state behind the consumer head). This means that the producer and consumer heads are pointing to the same cell. Now, since the requester loop did not issue any requests that means the producer head did not move from the start to the end of the requester loop, so at the very start of the requester loop, both the producer and consumer heads were pointing to the same cell, which is in the “a” state. That means that the previous run of the consumer loop must have ended with the consumer head pointing to a cell that is in the “a” state (it couldn’t have been in the “r” state because we only update the cell state from “r” to “a” in the completion loop, so the state of a cell cannot change from “r” to “a” from the start of the consumer loop to the end of the requester loop. Another way to think about this is that if the consumer loop did end with the consumer head pointing to a cell in the “r” state, then the cell would remain in the “r” state throughout the requester loop too, since the requester loop cannot turn “r” cells into “a” cells, which means the cell would be in the “r” state when entering the completion loop, which I’ve just explained cannot be the case here), which is impossible because the consumer will try to process all cells that are in the “a” state turning them into the “c” state, therefore it is impossible for the consumer head to be pointing at a cell that is in the “a” state at the end of the consumer loop.
Therefore we have proved that it is impossible for the completion loop to get stuck. The final loop, the consumer loop, also cannot get stuck because it simply loops through the array processing cells until it gets to a cell that is not in the “c” state, at which point it just terminates.
So, we have established that our single-threaded ring buffer implementation can never get stuck. What about correctness? Well, since we’re ensuring correctness by using the states, so we just need to ensure that the states are always correct. In the single-threaded implementation, the three loops are executed one after the other. This ensures that the states are always correct. When the requester loop terminates, the cells that it touched, i.e. transitioned into the “r” state, really are in the “r” state. And when the completion loop terminates, the cells that it touched, i.e. transitioned into the “a” state, really are in the “a” state. And when the consumer loop terminates, the cells that it touched, i.e. transitioned into the “c” state, really are in the “c” state. And since the loops run one after the other, it is guaranteed that the cell states are always correct from the perspective of each loop, so, for example, the consumer be confident that the cells that are in the “a” state really are available for it to process. In a multi-threaded implementation, synchronization is required in order to prevent the producer thread and the consumer thread from accessing cell states simultaneously, since that would be a data race and therefore undefined behavior.
Now, what about reissuing requests? For example, if a read request failed, or if you got a short read, then you may want to re-issue the read request (with updated parameters). Now, in my program, the consumer consumes in order while the producer also makes requests in order, but if you want to re-issue a request, then that means issuing a request for a block that you have already requested previously. But this is actually totally fine. Why is it okay? Because my program doesn’t actually care about the order in which requests are issued. All it cares about is that the producer and consumer heads move across the array one cell at a time, that the cells are mapped to the correct blocks, and that the state of the cell is always correct. That is to say, if a cell transitions into the “a” state then it MUST be okay for the consumer to process it. This is actually perfectly consistent with the use case where a read request returns an error or an incomplete read and you want to reissue the request - in that case, you just don’t transition the cell into the “a” state, instead, you keep it in the “r” state and just re-issue the request. From the perspective of the consumer as well as the producer, it just looks like the cell is staying in the “r” state longer than usual. You can implement this in the completion loop - if the syscall return value (the res field in the cqe) is not as expected, then you can just re-issue the request right there.
Overview
Here is a simple overview of how it works:
- Initially, the producer will start by sweeping through the array, moving the “requester head” forward, and the slots that it leaves behind are all initially marked as “requested but not yet completed”, and they will turn into “available for consumption” over time in an indeterminate order.
- The consumer follows by moving the “consumer head” forward as soon as the next slot becomes “available for consumption”, and leaves behind a trail of slots that are marked “already consumed”.
- The producer will eventually circle back to the start of the array, and it will wait for the first slot of the array to go into the “already consumed” state, because the only 2 other states are “requested but not yet completed” and “available for consumption” and it cannot issue a request for a slot which is in those states, since they are semantically “not consumed yet”.
So, the producer is continually waiting for the next slot to become “already consumed” while the consumer is continually waiting for the next slot to become “available for consumption”. The requester leaves behind a trail of slots that are “requested but not yet completed” which will all eventually turn into “available for consumption” while the consumer leaves behind a trail of slots that are “already consumed”.
Here is a diagram to illustrate this:
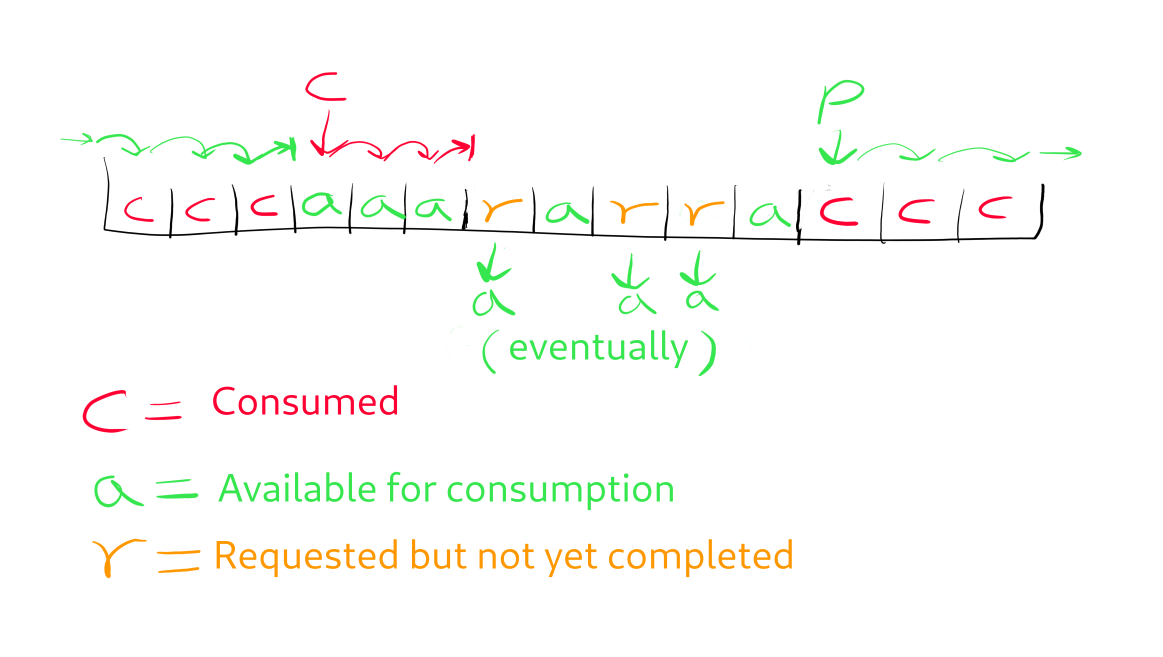
So in the diagram above, the P arrow denotes the position of the producer’s “requester head” (it’s a producer conceptually - doesn’t have to be an actual thread) while the C arrow denotes the consumer’s “consumer head”. As you can see, the producer’s “requester head” moves forward as long as there is a “c” (“already consumed”) slot in front of it while the consumer’s “consumer head” also moves forward as long as there is a “a” (“available for consumption”). So we can see that eventually, all the slots “behind” the requester head will become “a” while all the slots “behind” the consumer head are immediately marked as “c”. So we have the property that all the slots “in front of” the consumer head but “behind” the producer head will eventually become “a” while all of the slots “behind” the consumer head but “in front of” the producer head are always “c”. In the beginning all the slots are marked as “c” so the producer head will move first while the consumer head cannot move. Then as the producer leaves behind a trail of “r” some of those "r"s will turn into "a"s and so the consumer head will start moving too. Thus we established the main cycle where the producer moves forward consuming the "c"s and leaving behind "r"s which turn into "a"s while the consumer follows behind consuming the "a"s and turning them back into "c"s.
The multi-threaded implementation
In this section, I will explain how the multi-threaded implementation differs from the single-threaded implementation and why I think it’s correct and won’t get stuck. In order to understand this section, you need to have read the previous sections, which explain how the single-threaded implementation works and why I think it’s correct and won’t get stuck.
Here’s the code for the multi-threaded version of my program:
/* SPDX-License-Identifier: MIT */
/*
* Compile with: g++ -Wall -O3 -D_GNU_SOURCE liburing_b3sum_multithread.cc -luring libblake3.a -o liburing_b3sum_multithread
* For an explanation of how this code works, see my article/blog post: https://1f604.com/b3sum
*
* Note: the comments in this program are copied unchanged from the single-threaded implementation in order to make it easier for a reader using `diff` to see the code changes from the single-thread version
*
* This program is a modified version of the liburing cp program from Shuveb Hussain's io_uring tutorial.
* Original source code here: https://github.com/axboe/liburing/blob/master/examples/io_uring-cp.c
* The modifications were made by 1f604.
*
* The official io_uring documentation can be seen here:
* - https://kernel.dk/io_uring.pdf
* - https://kernel-recipes.org/en/2022/wp-content/uploads/2022/06/axboe-kr2022-1.pdf
*
* Acronyms: SQ = submission queue, SQE = submission queue entry, CQ = completion queue, CQE = completion queue event
*/
#include "blake3.h"
#include "liburing.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <assert.h>
#include <sys/ioctl.h>
// Multithreading stuff
#include <atomic>
#include <thread>
/* Constants */
static const int ALIGNMENT = 4 * 1024; // Needed only because O_DIRECT requires aligned memory
/* ===============================================
* ========== Start of global variables ==========
* ===============================================
* Declared static because they are only supposed to be visible within this .c file.
*
* --- Command line options ---
* The following variables are set by the user from the command line.
*/
static int g_queuedepth; /* This variable is not really the queue depth, but is more accurately described as
* "the limit on the number of incomplete requests". Allow me to explain.
* io_uring allows you to have more requests in-flight than the size of your submission
* (and completion) queues. How is this possible? Well, when you call io_uring_submit,
* normally it will submit ALL of the requests in the submission queue, which means that
* when the call returns, your submission queue is now empty, even though the requests
* are still "in-flight" and haven't been completed yet!
* In earlier kernels, you could overflow the completion queue because of this.
* Thus it says in the official io_uring documentation (https://kernel.dk/io_uring.pdf):
* Since the sqe lifetime is only that of the actual submission of it, it's possible
* for the application to drive a higher pending request count than the SQ ring size
* would indicate. The application must take care not to do so, or it could risk
* overflowing the CQ ring.
* That is to say, the official documentation recommended that applications should ensure
* that the number of in-flight requests does not exceed the size of the submission queue.
* This g_queuedepth variable is therefore a limit on the total number of "incomplete"
* requests, which is the number of requests on the submission queue plus the number of
* requests that are still "in flight".
* See num_unfinished_requests for details on how this is implemented. */
static int g_use_o_direct; // whether to use O_DIRECT
static int g_process_in_inner_loop; // whether to process the data inside the inner loop
static int g_use_iosqe_io_drain; // whether to issue requests with the IOSQE_IO_DRAIN flag
static int g_use_iosqe_io_link; // whether to issue requests with the IOSQE_IO_LINK flag
//static int g_use_ioring_setup_iopoll; // when I enable either IORING_SETUP_SQPOLL or IORING_SETUP_IOPOLL, on my current system,
//static int g_use_ioring_setup_sqpoll; // it turns my process into an unkillable zombie that uses 100% CPU that never terminates.
// when I was using encrypted LVM, it just gave me error: Operation not supported.
// I decided to not allow users to enable these options because I didn't want them
// to accidentally launch an unkillable never-ending zombie process that uses 100% CPU.
// I observed this problem in fio too when I enabled --hipri on fio, it also turned into
// an unkillable never-ending zombie process that uses 100% CPU.
static size_t g_blocksize; // This is the size of each buffer in the ringbuf, in bytes.
// It is also the size of each read from the file.
static size_t g_numbufs; // This is the number of buffers in the ringbuf.
/* --- Non-command line argument global variables --- */
blake3_hasher g_hasher;
static int g_filedescriptor; // This is the file descriptor of the file we're hashing.
static size_t g_filesize; // This will be filled in by the function that gets the file size.
static size_t g_num_blocks_in_file; // The number of blocks in the file, where each block is g_blocksize bytes.
// This will be calculated by a ceiling division of filesize by blocksize.
static size_t g_size_of_last_block; // The size of the last block in the file. See calculate_numblocks_and_size_of_last_block.
static int producer_head = 0; // Position of the "producer head". see explanation in my article/blog post
static int consumer_head = 0; // Position of the "consumer head". see explanation in my article/blog post
#define AVAILABLE_FOR_CONSUMPTION 1
#define ALREADY_CONSUMED 2
#define REQUESTED_BUT_NOT_YET_COMPLETED 3
struct my_custom_data { // This is the user_data associated with read requests, which are placed on the submission ring.
// In applications using io_uring, the user_data struct is generally used to identify which request a
// completion is for. In the context of this program, this structure is used both to identify which
// block of the file the read syscall had just read, as well as for the producer and consumer to
// communicate with each other, since it holds the cell state.
// This can be thought of as a "cell" in the ring buffer, since it holds the state of the cell as well
// as a pointer to the data (i.e. a block read from the file) that is "in" the cell.
// Note that according to the official io_uring documentation, the user_data struct only needs to be
// valid until the submit is done, not until completion. Basically, when you submit, the kernel makes
// a copy of user_data and returns it to you with the CQE (completion queue entry).
unsigned char* buf_addr; // Pointer to the buffer where the read syscall is to place the bytes from the file into.
size_t nbytes_expected; // The number of bytes we expect the read syscall to return. This can be smaller than the size of the buffer
// because the last block of the file can be smaller than the other blocks.
//size_t nbytes_to_request; // The number of bytes to request. This is always g_blocksize. I made this decision because O_DIRECT requires
// nbytes to be a multiple of filesystem block size, and it's simpler to always just request g_blocksize.
off_t offset_of_block_in_file; // The offset of the block in the file that we want the read syscall to place into the memory location
// pointed to by buf_addr.
std::atomic_int state; // Describes whether the item is available to be hashed, already hashed, or requested but not yet available for hashing.
int ringbuf_index; // The slot in g_ringbuf where this "cell" belongs.
// I added this because once we submit a request on submission queue, we lose track of it.
// When we get back a completion, we need an identifier to know which request the completion is for.
// Alternatively, we could use something to map the buf_addr to the ringbuf_index, but this is just simpler.
};
// multithreading function
static void update_cell_state(struct my_custom_data* data, int new_state) { // State updates need to be synchronized because both threads look at the state
// In effect they communicate via state updates.
// both the consumer and producer threads block/wait for state change to continue
data->state = new_state;
}
struct my_custom_data* g_ringbuf; // This is a pointer to an array of my_custom_data structs. These my_custom_data structs can be thought of as the
// "cells" in the ring buffer (each struct contains the cell state), thus the array that this points to can be
// thought of as the "ring buffer" referred to in my article/blog post, so read that to understand how this is used.
// See the allocate_ringbuf function for details on how and where the memory for the ring buffer is allocated.
/* ===============================================
* =========== End of global variables ===========
* ===============================================*/
static int setup_io_uring_context(unsigned entries, struct io_uring *ring)
{
int rc;
int flags = 0;
rc = io_uring_queue_init(entries, ring, flags);
if (rc < 0) {
fprintf(stderr, "queue_init: %s\n", strerror(-rc));
return -1;
}
return 0;
}
static int get_file_size(int fd, size_t *size)
{
struct stat st;
if (fstat(fd, &st) < 0)
return -1;
if (S_ISREG(st.st_mode)) {
*size = st.st_size;
return 0;
} else if (S_ISBLK(st.st_mode)) {
unsigned long long bytes;
if (ioctl(fd, BLKGETSIZE64, &bytes) != 0)
return -1;
*size = bytes;
return 0;
}
return -1;
}
static void add_read_request_to_submission_queue(struct io_uring *ring, size_t expected_return_size, off_t fileoffset_to_request)
{
assert(fileoffset_to_request % g_blocksize == 0);
int block_number = fileoffset_to_request / g_blocksize; // the number of the block in the file
/* We do a modulo to map the file block number to the index in the ringbuf
e.g. if ring buf_addr has 4 slots, then
file block 0 -> ringbuf index 0
file block 1 -> ringbuf index 1
file block 2 -> ringbuf index 2
file block 3 -> ringbuf index 3
file block 4 -> ringbuf index 0
file block 5 -> ringbuf index 1
file block 6 -> ringbuf index 2
And so on.
*/
int ringbuf_idx = block_number % g_numbufs;
struct my_custom_data* my_data = &g_ringbuf[ringbuf_idx];
assert(my_data->ringbuf_index == ringbuf_idx); // The ringbuf_index of a my_custom_data struct should never change.
my_data->offset_of_block_in_file = fileoffset_to_request;
assert (my_data->buf_addr); // We don't need to change my_data->buf_addr since we set it to point into the backing buffer at the start of the program.
my_data->nbytes_expected = expected_return_size;
update_cell_state(my_data, REQUESTED_BUT_NOT_YET_COMPLETED);
/*my_data->state = REQUESTED_BUT_NOT_YET_COMPLETED; /* At this point:
* 1. The producer is about to send it off in a request.
* 2. The consumer shouldn't be trying to read this buffer at this point.
* So it is okay to set the state to this here.
*/
struct io_uring_sqe* sqe = io_uring_get_sqe(ring);
if (!sqe) {
puts("ERROR: FAILED TO GET SQE");
exit(1);
}
io_uring_prep_read(sqe, g_filedescriptor, my_data->buf_addr, g_blocksize, fileoffset_to_request);
// io_uring_prep_read sets sqe->flags to 0, so we need to set the flags AFTER calling it.
if (g_use_iosqe_io_drain)
sqe->flags |= IOSQE_IO_DRAIN;
if (g_use_iosqe_io_link)
sqe->flags |= IOSQE_IO_LINK;
io_uring_sqe_set_data(sqe, my_data);
}
static void increment_buffer_index(int* head) // moves the producer or consumer head forward by one position
{
*head = (*head + 1) % g_numbufs; // wrap around when we reach the end of the ringbuf.
}
static void consumer_thread() // Conceptually, this resumes the consumer "thread".
{ // As this program is single-threaded, we can think of it as cooperative multitasking.
for (int i = 0; i < g_num_blocks_in_file; ++i){
while (g_ringbuf[consumer_head].state != AVAILABLE_FOR_CONSUMPTION) {} // busywait
// Consume the item.
// The producer has already checked that nbytes_expected is the same as the amount of bytes actually returned.
// If the read syscall returned something different to nbytes_expected then the program would have terminated with an error message.
// Therefore it is okay to assume here that nbytes_expected is the same as the amount of actual data in the buffer.
blake3_hasher_update(&g_hasher, g_ringbuf[consumer_head].buf_addr, g_ringbuf[consumer_head].nbytes_expected);
// We have finished consuming the item, so mark it as consumed and move the consumer head to point to the next cell in the ringbuffer.
update_cell_state(&g_ringbuf[consumer_head], ALREADY_CONSUMED);
increment_buffer_index(&consumer_head);
}
// Finalize the hash. BLAKE3_OUT_LEN is the default output length, 32 bytes.
uint8_t output[BLAKE3_OUT_LEN];
blake3_hasher_finalize(&g_hasher, output, BLAKE3_OUT_LEN);
// Print the hash as hexadecimal.
printf("BLAKE3 hash: ");
for (size_t i = 0; i < BLAKE3_OUT_LEN; ++i) {
printf("%02x", output[i]);
}
printf("\n");
}
static void producer_thread()
{
int rc;
unsigned long num_blocks_left_to_request = g_num_blocks_in_file;
unsigned long num_blocks_left_to_receive = g_num_blocks_in_file;
unsigned long num_unfinished_requests = 0;
/* A brief note on how the num_unfinished_requests variable is used:
* As mentioned earlier, in io_uring it is possible to have more requests in-flight than the
* size of the completion ring. In earlier kernels this could cause the completion queue to overflow.
* In later kernels there was an option added (IORING_FEAT_NODROP) which, when enabled, means that
* if a completion event occurs and the completion queue is full, then the kernel will internally
* store the event until the completion queue has room for more entries.
* Therefore, on newer kernels, it isn't necessary, strictly speaking, for the application to limit
* the number of in-flight requests. But, since it is almost certainly the case that an application
* can submit requests at a faster rate than the system is capable of servicing them, if we don't
* have some backpressure mechanism, then the application will just keep on submitting more and more
* requests, which will eventually lead to the system running out of memory.
* Setting a hard limit on the total number of in-flight requests serves as a backpressure mechanism
* to prevent the number of requests buffered in the kernel from growing without bound.
* The implementation is very simple: we increment num_unfinished_requests whenever a request is placed
* onto the submission queue, and decrement it whenever an entry is removed from the completion queue.
* Once num_unfinished_requests hits the limit that we set, then we cannot issue any more requests
* until we receive more completions, therefore the number of new completions that we receive is exactly
* equal to the number of new requests that we will place, thus ensuring that the number of in-flight
* requests can never exceed g_queuedepth.
*/
off_t next_file_offset_to_request = 0;
struct io_uring uring;
if (setup_io_uring_context(g_queuedepth, &uring)) {
puts("FAILED TO SET UP CONTEXT");
exit(1);
}
struct io_uring* ring = ů
while (num_blocks_left_to_receive) { // This loop consists of 3 steps:
// Step 1. Submit read requests.
// Step 2. Retrieve completions.
// Step 3. Run consumer.
/*
* Step 1: Make zero or more read requests until g_queuedepth limit is reached, or until the producer head reaches
* a cell that is not in the ALREADY_CONSUMED state (see my article/blog post for explanation).
*/
unsigned long num_unfinished_requests_prev = num_unfinished_requests; // The only purpose of this variable is to keep track of whether
// or not we added any new requests to the submission queue.
while (num_blocks_left_to_request) {
if (num_unfinished_requests >= g_queuedepth)
break;
// wait for state to change
if (g_ringbuf[producer_head].state != ALREADY_CONSUMED)
break;
/* expected_return_size is the number of bytes that we expect this read request to return.
* expected_return_size will be the block size until the last block of the file.
* when we get to the last block of the file, expected_return_size will be the size of the last
* block of the file, which is calculated in calculate_numblocks_and_size_of_last_block
*/
size_t expected_return_size = g_blocksize;
if (num_blocks_left_to_request == 1) // if we're at the last block of the file
expected_return_size = g_size_of_last_block;
add_read_request_to_submission_queue(ring, expected_return_size, next_file_offset_to_request);
next_file_offset_to_request += expected_return_size;
++num_unfinished_requests;
--num_blocks_left_to_request;
// We have added a request for the read syscall to write into the cell in the ringbuffer.
// The add_read_request_to_submission_queue has already marked it as REQUESTED_BUT_NOT_YET_COMPLETED,
// so now we just need to move the producer head to point to the next cell in the ringbuffer.
increment_buffer_index(&producer_head);
}
// If we added any read requests to the submission queue, then submit them.
if (num_unfinished_requests_prev != num_unfinished_requests) {
rc = io_uring_submit(ring);
if (rc < 0) {
fprintf(stderr, "io_uring_submit: %s\n", strerror(-rc));
exit(1);
}
}
/*
* Step 2: Remove all the items from the completion queue.
*/
bool first_iteration = 0; // On the first iteration of the loop, we wait for at least one cqe to be available,
// then remove one cqe.
// On each subsequent iteration, we try to remove one cqe without waiting.
// The loop terminates only when there are no more items left in the completion queue,
while (num_blocks_left_to_receive) { // Or when we've read in all of the blocks of the file.
struct io_uring_cqe *cqe;
if (first_iteration) { // On the first iteration we always wait until at least one cqe is available
rc = io_uring_wait_cqe(ring, &cqe); // This should always succeed and give us one cqe.
first_iteration = 0;
} else {
rc = io_uring_peek_cqe(ring, &cqe); // This will fail once there are no more items left in the completion queue.
if (rc == -EAGAIN) { // A return code of -EAGAIN means that there are no more items left in the completion queue.
break;
}
}
if (rc < 0) {
fprintf(stderr, "io_uring_peek_cqe: %s\n",
strerror(-rc));
exit(1);
}
assert(cqe);
// At this point we have a cqe, so let's see what our syscall returned.
struct my_custom_data *data = (struct my_custom_data*) io_uring_cqe_get_data(cqe);
// Check if the read syscall returned an error
if (cqe->res < 0) {
// we're not handling EAGAIN because it should never happen.
fprintf(stderr, "cqe failed: %s\n",
strerror(-cqe->res));
exit(1);
}
// Check if the read syscall returned an unexpected number of bytes.
if ((size_t)cqe->res != data->nbytes_expected) {
// We're not handling short reads because they should never happen on a disk-based filesystem.
if ((size_t)cqe->res < data->nbytes_expected) {
puts("panic: short read");
} else {
puts("panic: read returned more data than expected (wtf). Is the file changing while you're reading it??");
}
exit(1);
}
assert(data->offset_of_block_in_file % g_blocksize == 0);
// If we reach this point, then it means that there were no errors: the read syscall returned exactly what we expected.
// Since the read syscall returned, this means it has finished filling in the cell with ONE block of data from the file.
// This means that the cell can now be read by the consumer, so we need to update the cell state.
update_cell_state(&g_ringbuf[data->ringbuf_index], AVAILABLE_FOR_CONSUMPTION);
--num_blocks_left_to_receive; // We received ONE block of data from the file
io_uring_cqe_seen(ring, cqe); // mark the cqe as consumed, so that its slot can get reused
--num_unfinished_requests;
//if (g_process_in_inner_loop)
// resume_consumer();
}
/* Step 3: Run consumer. This might be thought of as handing over control to the consumer "thread". See my article/blog post. */
//resume_consumer();
}
//resume_consumer();
close(g_filedescriptor);
io_uring_queue_exit(ring);
}
static void process_cmd_line_args(int argc, char* argv[])
{
if (argc != 9) {
printf("%s: infile g_blocksize g_queuedepth g_use_o_direct g_process_in_inner_loop g_numbufs g_use_iosqe_io_drain g_use_iosqe_io_link\n", argv[0]);
exit(1);
}
g_blocksize = atoi(argv[2]) * 1024; // The command line argument is in KiBs
g_queuedepth = atoi(argv[3]);
if (g_queuedepth > 32768)
puts("Warning: io_uring queue depth limit on Kernel 6.1.0 is 32768...");
g_use_o_direct = atoi(argv[4]);
g_process_in_inner_loop = atoi(argv[5]);
g_numbufs = atoi(argv[6]);
g_use_iosqe_io_drain = atoi(argv[7]);
g_use_iosqe_io_link = atoi(argv[8]);
}
static void open_and_get_size_of_file(const char* filename)
{
if (g_use_o_direct){
g_filedescriptor = open(filename, O_RDONLY | O_DIRECT);
puts("opening file with O_DIRECT");
} else {
g_filedescriptor = open(filename, O_RDONLY);
puts("opening file without O_DIRECT");
}
if (g_filedescriptor < 0) {
perror("open file");
exit(1);
}
if (get_file_size(g_filedescriptor, &g_filesize)){
puts("Failed getting file size");
exit(1);
}
}
static void calculate_numblocks_and_size_of_last_block()
{
// this is the mathematically correct way to do ceiling division
// (assumes no integer overflow)
g_num_blocks_in_file = (g_filesize + g_blocksize - 1) / g_blocksize;
// calculate the size of the last block of the file
if (g_filesize % g_blocksize == 0)
g_size_of_last_block = g_blocksize;
else
g_size_of_last_block = g_filesize % g_blocksize;
}
static void allocate_ringbuf()
{
// We only make 2 memory allocations in this entire program and they both happen in this function.
assert(g_blocksize % ALIGNMENT == 0);
// First, we allocate the entire underlying ring buffer (which is a contiguous block of memory
// containing all the actual buffers) in a single allocation.
// This is one big piece of memory which is used to hold the actual data from the file.
// The buf_addr field in the my_custom_data struct points to a buffer within this ring buffer.
unsigned char* ptr_to_underlying_ring_buffer;
// We need aligned memory, because O_DIRECT requires it.
if (posix_memalign((void**)&ptr_to_underlying_ring_buffer, ALIGNMENT, g_blocksize * g_numbufs)) {
puts("posix_memalign failed!");
exit(1);
}
// Second, we allocate an array containing all of the my_custom_data structs.
// This is not an array of pointers, but an array holding all of the actual structs.
// All the items are the same size, which makes this easy
g_ringbuf = (struct my_custom_data*) malloc(g_numbufs * sizeof(struct my_custom_data));
// We partially initialize all of the my_custom_data structs here.
// (The other fields are initialized in the add_read_request_to_submission_queue function)
off_t cur_offset = 0;
for (int i = 0; i < g_numbufs; ++i) {
g_ringbuf[i].buf_addr = ptr_to_underlying_ring_buffer + cur_offset; // This will never change during the runtime of this program.
cur_offset += g_blocksize;
// g_ringbuf[i].bufsize = g_blocksize; // all the buffers are the same size.
g_ringbuf[i].state = ALREADY_CONSUMED; // We need to set all cells to ALREADY_CONSUMED at the start. See my article/blog post for explanation.
g_ringbuf[i].ringbuf_index = i; // This will never change during the runtime of this program.
}
}
int main(int argc, char *argv[])
{
assert(sizeof(size_t) >= 8); // we want 64 bit size_t for files larger than 4GB...
process_cmd_line_args(argc, argv); // we need to first parse the command line arguments
open_and_get_size_of_file(argv[1]);
calculate_numblocks_and_size_of_last_block();
allocate_ringbuf();
// Initialize the hasher.
blake3_hasher_init(&g_hasher);
// Run the threads
std::thread t1(producer_thread), t2(consumer_thread);
t1.join();
t2.join();
}
There are only a few differences between the single-threaded and the multi-threaded versions, two of which are crucial, as I will explain. Well, let’s start with the unimportant differences. So, to begin with, the multi-threaded version makes use of std::thread (added in C++11) so it has to be compiled using g++, which actually can compile C code too…so you might as well use g++ to compile both the singlethreaded and multithreaded versions. So the only two new includes are <atomic and <thread>. Well, since we’re doing multithreading using std::thread, it’s obvious why <thread> had to be included. But why the <atomic>? Why not <mutex> or <condition_variable>? That’s because we’re doing synchronization using atomics instead of using mutexes or condition variables.
One of the two crucial changes is the change in the type of the state field of the my_custom_data struct, from an enum to an std::atomic_int. This is absolutely necessary because otherwise you can have the producer writing to state while the consumer is reading from it “at the same time” (or vice versa. For the formal definition of exactly what “at the same time” means in this context, see my blog post here: https://1f604.blogspot.com/2023/06/atomic-weapons-part-1.html), which is a data race. It needs to be an atomic because you need the consumer thread to “see” all of the changes that the producer thread made to memory, in this case the producer thread is filling the buffers with data from the file. The atomic solves the problem because a write to an atomic is a store/release while a read from an atomic is a load/acquire, and it is guaranteed that, if thread A writes to an atomic and thread B reads that same atomic, then whenever thread B reads the atomic and sees a certain value, then everything that thread A did prior to writing that value to that atomic will become immediately visible to B as soon as B reads that atomic. In this case this means that, as soon as the consumer thread reads the state, it will “see” all of the blocks that the producer filled prior to writing to the state variable. More specifically, if thread A only ever sets the state of a cell to “a” after ensuring that the read syscall has finished writing to that cell (i.e. that cell is now filled with a block from the file), then if thread B sees that the state of a cell is “a”, then it is guaranteed that thread B will also see the changes that the read syscall had made to the cell i.e. the fully written data. Another way to think about this is that the producer and consumer threads are conceptually communicating with each other via the state variable - this is shared memory, and both threads will both read and write to it, therefore access to it must be synchronized otherwise the two threads can access it simultaneously which is a data race which is undefined behavior.
Now, as explained earlier, the consumer thread needs to wait for the cell that the consumer head is pointing to to go into the “a” state before continuing. In the single-threaded version, it was simply implemented as a loop that exited when it encountered a non-“a” cell. But now that it is in a separate thread, we can finally replace the consumer loop with a direct implementation of the consumer thread concept, which is a loop that will consume the current cell as soon as the cell goes into the “a” state, and then advance to the cell and repeat. But this requires us now to implement a “wait” where we previously did not have any waits in the consumer loop, because the consumer needs to wait for the cell to go into the “a” state before it can process it. Anyway, using an atomic to implement a wait is trivial - you just write a while loop with nothing in the body like this: while(current_cell.state is not "a") {}. This is known as a “busy wait”, and although is supposedly quite good for performance, I did not notice any difference in performance between the busy-wait version and the condition-variable-wait version for the “allocate enough memory to hold the entire file” version of my program, so I doubt the busy-wait yields any performance benefits here. Rather, I chose to use it because I think it’s easier to reason about.
The other crucial change in my program is the change from bool first_iteration = 1; to bool first_iteration = 0;. Why is this a crucial change? Because without it the program could get stuck. How? Recall that in our single-threaded program, the completion loop waits for a completion in its first iteration. Now that we have converted the producer function into a thread, retaining this wait could cause the program to get stuck. Allow me to demonstrate.

The above diagram shows a ring buffer with 2 slots. To begin with, all the cells are in the “c” state. Now the consumer is blocked waiting for slot 0 to turn into the “a” state, while the producer starts the requester loop and iterates through the array turning all the cells in the “a” state into the “r” state. So now, cells 0 and 1 are both in the “r” state. What happens next is that, since the producer is now no longer able to issue new requests, it goes into the completion loop and becomes blocked waiting for a completion event. So far so good. Next, a completion comes in for slot 0, so the producer sets the state of that cell to “a”, which means the consumer is now unblocked and so the consumer begins processing cell 0. Now the producer is unblocked and can continue, so it goes back to the requester loop and finds that there’s nothing to do, so it then goes back to the completion loop and waits for the next completion. Now the consumer is still processing cell 0, and the producer is waiting for the next completion. At this point, either the consumer could finish processing the cell first, or the completion event could arrive first. Suppose the completion event arrives first. Then the producer will transition cell 1 into the “a” state, so that now both cells are in the “a” state. The producer will then go back into the requester loop, then, it will find that it cannot advance the producer head, since cell 0 is still in the “a” state (the consumer hasn’t finished yet) so it will exit the requester loop and begin the completion loop, waiting for the next completion event. That’s where the problem occurs: both cells are now in the “a” state, meaning no more requests are in flight so there will be no completion events! The consumer will finish processing cell 0, transitioning it into the “c” state, but the producer is still waiting for a completion! Then the consumer will finish processing cell 1, transitioning it into the “c” state, but the producer is still waiting for a completion, which will never arrive because no requests are in flight!!! So that’s why it’s absolutely crucial to remove the wait in the first iteration of the completion loop, because otherwise the program can get stuck.
So, is this program correct? Let’s think about the correctness property, which is that the consumer must process all of the blocks of the file in order, and once each. To show this, it is sufficient to show that the consumer will only process a cell when it is okay for it to process that cell. We use the cell states to guarantee this property, and we said that if the states are always correct, then the program will be correct too. Let’s think about what it means for the states to always be correct.
From the consumer’s perspective, that means that whenever the consumer sees that a cell is in the “a” state, then that always means it really is safe for the consumer to process it. It is okay for a cell to be safe to be process but to not be in the “a” state, because the consumer will simply not consume it and nothing bad will happen. So the correctness from the consumer’s perspective is only that if a cell is in the “a” state then it really is okay to process, and the producer guarantees that by first getting the completion event and then writing to the state to update it, thus ensuring that when the consumer sees that the cell state has been changed to “a”, the consumer also will see the changes that the producer made to the cell (i.e. filling it in with a block from the file).
From the producer’s perspective, that means that whenever the producer sees that a cell is in the “c” state, then that always means it really is safe for the producer to issue a request for that cell. It is okay for a cell to be safe-to-issue-a-request-for but to not be in the “c” state, because the producer will simply do nothing so nothing bad will happen. So the correctness from the producer’s perspective is only that if a cell is in the “c” state then it really is okay to issue a request for it, and the consumer guarantees this by first processing the cell and then updating the cell state to “c” - it updates the cell state only after it has finished processing the cell, thus ensuring that whenever the producer sees that the cell state has been changed to “c”, that means the consumer is already done with that block and doesn’t need the data in that cell anymore.
So, by ensuring that the cell states are always correct, we ensure that the consumer will only process a block when it is really okay to process that block, and that the producer will only issue a request for a block when it is really okay to issue a request for that block. That is to say, the consumer will only read a block when it is okay to read that block, and the producer will only write a block when it is okay to write to that block.
Now, what about the eventually-terminates property? We want to show that the program can never get stuck. Let’s start by looking at the consumer, since if we can prove that the consumer will never get stuck then that’s good enough to show that the program will never get stuck. The consumer thread is extremely simple - it just waits for the state to become “a”. So the only way that the consumer can get stuck is if the cell that it’s waiting on never turns into “a” - that means it either remains “r” forever or remains “c” forever. It is the job of the producer to transition cells into the “a” state (from either the “r” or the “c” state), which means that the consumer can only get stuck if the producer gets stuck. So now we have to look at the producer.
Can the producer get stuck? The producer thread consists of two loops: a requester loop followed by a completion loop. The requester loop will place requests on the SQ until it can no longer put any more requests on the SQ (either because the number of incomplete requests has reached the queue depth, or because the cell that the producer head is pointing to is not in the “c” state), at which point it will terminate and submit the requests. Then the producer thread will enter the completion loop where it will go through the completions in the completion queue, removing them and transitioning the appropriate cells to the “a” state, until there are no more completions left in the completion queue, at which point the completion loop will terminate. The major difference, as explained earlier, between the multi-threaded and single-threaded version, is that the single-threaded version will wait for a completion in the first iteration of the completion loop, whereas the multi-threaded version will not. In the multi-threaded version, if in the first iteration of the completion loop there were no completions in the completion queue, then the completion loop will terminate immediately without waiting. And likewise for the requester loop (which has always been the case anyway) - if it cannot place a request then the requester loop will just terminate immediately.
The producer essentially has 2 jobs: firstly, it constantly checks the cell that the producer head is pointing to, waiting for it to go into the “c” state so that it can then issue a request for it, thus doing the job of transitioning the cell pointed to by the producer head from the “c” state into the “r” state, and secondly, it constantly checks for completions, thus doing the job of transitioning cells from the “r” state to the “a” state. There is no “wait”, the producer is constantly executing these two loops one after the other. There are no blocking instructions within these two loops, it’s just “issue requests until you can’t” and then “pop from the completion queue until you can’t”. It is therefore easy to see that each loop runs in a finite amount of time - the requester loop will always eventually terminate, because eventually the producer will no longer be able to advance the producer head (either because it reached a cell that is not in the “c” state, or because it has reached the limit of unfinished requests) - to see this, imagine a consumer that is infinitely fast, so all the “a” cells immediately turn into “c” cells as soon as the consumer moves through them. Even in this case, the requester loop will still terminate because it needs to run the completion loop in order to turn the “r” cells into “a” cells, meaning eventually the ring buffer will be filled with “r” cells thus forcing the requester loop to terminate. The completion loop will always terminate because there is always only a finite number of in-flight requests at any given moment, and it cannot issue new requests while it is in the completion loop, therefore each complete iteration of the completion loop reduces the number of in-flight requests by 1, so eventually there will be no in-flight requests and so the completion queue will be empty and so the completion loop will terminate. Therefore, both the requester loop and the completion loop are guaranteed to terminate, which means that the producer will always be constantly doing the two jobs one after the other - it cannot get stuck on one job.
So, in what situation can the producer get stuck? Well, it cannot really get stuck in the sense of being permanently blocked on a wait, since it is always running the two loops one after the other. What that means is that we can be assured that cells in the “r” state will always eventually transition into the “a” state, because that is what the second loop of the producer does. The other job that the producer has is transitioning cells in the “c” state into the “r” state, and here again we’ve established that whenever the cell pointed to by the producer head transitions into the “c” state, it is guaranteed to eventually transition into the “r” state, because that’s what the producer’s first loop does.
The only way for the producer to get stuck, then, is for the producer head to always be waiting for the cell that it’s pointing to to transition into the “c” state. Now, if the cell is in the “r” state then it will eventually transition into the “a” state as explained above, therefore we can simply consider the case where the cell is in the “a” state. Actually, this applies to the entire ring buffer - since it is guaranteed that “r” cells will always eventually turn into “a” cells, so we should consider any situation in which the producer head is stuck as a situation where all the cells in the ring buffer are in either the “a” state or the “c” state. Here is an example of such a situation
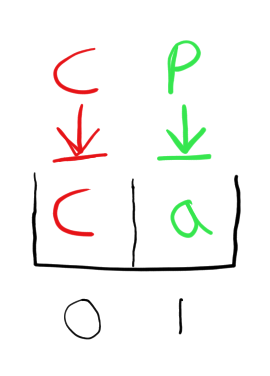
In the above situation, the producer is stuck waiting for the cell under P to transition into the “c” state while the consumer is stuck waiting for the cell under C to transition into the “a” state. It is necessary for both heads to be stuck, because if one head is not stuck then eventually it will make its way to the other head and unblock the other head. For example, if the consumer is not stuck, then it will eventually make its way to P and turn the cell under P into the “c” state. Likewise, if the producer is not stuck, then it will eventually make its way to C and turn the cell under C into the “r” state which will eventually turn into the “a” state. Therefore, in order for one to be stuck, the other must be stuck as well. That is to say, in order for the consumer to be stuck, the producer must also be stuck, and in order for the producer to be stuck, the consumer must also be stuck. Thus, in order for the program to get stuck, we have to have a situation where both the producer and the consumer are simultaneously stuck.
Therefore, in order to prove that the program won’t get stuck, we just need to prove that it’s impossible for the consumer and the producer to be stuck at the same time. Let’s start from the beginning of the program. At the beginning of the program, all the cells are in the “c” state and only the producer head can move. The producer will then begin moving across the ring buffer turning “c” cells into “r” cells which turn into “a” cells, and the consumer head will follow. Now, in what situation would the producer get stuck? It will get stuck when the producer head points to a cell that is in the “r” or “a” state. Now, since the producer is the only one that can transition a cell into the “r” or “a” state, and the ring buffer starts off with all cells in the “c” state, and the producer moves forward one cell at a time, turning each cell it touches into the “r” state (which becomes the “a” state), this means that the only way that it is possible for the producer to be blocked on a cell that is in the “r” or “a” state is if the producer has already gone the whole way around the ring buffer i.e. that the entire ring buffer is now full of cells that are either in the “r” or “a” state. To visualize this, imagine that to begin with all the cells are in the “c” state, and as the producer moves forward it is like a snake with a body/tail made of cells in the “r” state which turn into the “a” state, while the consumer is like another snake with a body/tail made of cells in the “c” state, and the consumer snake follows behind the producer snake. If the producer is faster than the consumer, eventually it will “eat up” all of those cells in the “c” state and catch up to its own tail…that is the only way that it can ever reach a cell in the “a” or “r” state.
Thus, because of the starting arrangement of the ring buffer (all cells in the “c” state), the only possible situation where the producer is stuck is if all of the cells in the ring buffer are either in the “r” state or the “a” state, and we know that all the “r” cells will eventually transition into “a” cells, so eventually the ring buffer will be filled entirely with “a” cells. But, in this state, the consumer cannot possibly be stuck, because it’s not waiting on anything! Therefore, in the ONLY possible scenario where the producer is stuck, the consumer is not stuck, therefore there can never be a situation where both the producer and the consumer are stuck, and since we’ve previously established that the program cannot be stuck unless the producer and the consumer are both stuck at the same time, this means that the program can never be stuck.
How many requests are actually in-flight?
A natural question to ask is what are some good sizes for the queue depth and ring buffer size? I’ve found that very small numbers, in the range of 2-4, worked quite well for the single-threaded O_DIRECT version. I wrote an instrumented version of the single-threaded ring buffer implementation, and saw that with a queue depth and ring buffer size of 4, the number of in-flight requests when entering the consumer loop is always 3, which makes perfect sense - on my machine, the hashing speed is greater than the file read speed, which means that the consumer will consume a block as soon as it is returned by the read syscall. Therefore, if we place requests for the next 4 blocks, and wait for at least one block to be returned, the result is that as soon as the first block returns, the completion loop will finish and the consumer loop will run, consuming that block. We then go back to the requester loop which issues 1 request, and then wait on the completion queue again. Since the wait finished as soon as we got the block back, the disk had just barely started reading the next block of the file when the CPU started processing the block. Since the CPU is able to process blocks significantly faster than the disk can return blocks, by the time the CPU is finished processing the block, the disk hasn’t finished reading in the next block of the file yet, and so we have to wait again. Hence, the number of requests in-flight is always one less than the queue depth and ring buffer size, so it’s always 3 if the queue depth and ring buffer size is 4, and it’s always 1 if the queue depth and ring buffer size is 2:
$ echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./instru 1GB.txt 512 4 1 0 4 0 0
opening file with O_DIRECT
BLAKE3 hash: 90e7144c7a091d505102e433fb4f2160d1d56d7f5b39291206819e5648c1e639
Number of requests in-flight:
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 1, 0, 0,
Num records: 2049
real 0m0.302s
user 0m0.237s
sys 0m0.022s
I suppose the natural follow up question is: what would we see instead if the CPU was slower than the disk? Suppose the queue depth and the ring buffer size was 4. Then initially, the requester loop issues 4 requests, and the completion loop gets one block, so now there are 3 requests in flight. Now, the consumer loop runs, but by the time the consumer has finished, suppose the disk has already retrieved the next 2 blocks of the file, so now there is only 1 request in flight. Then the requester loop runs again and issues 1 new request, so now there are only 2 requests in flight. This time the completion loop returns 2 blocks instead of 1, and now the consumer has to consume both of those blocks. By the time the consumer has finished processing those 2 blocks, the disk would have already finished reading in the other 2 blocks that were in flight, and has spent some time idle. But, when the consumer loop began, there were two blocks in flight, even though by the time the consumer loop ended, those two requests had long been finished. And indeed, when I run the code with a deliberately slowed down consumer, I see that the recorded number of in-flight requests at the start of the consumer loop is mostly 2 (occasionally 3):
$ echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_singlethread_instrumented 1GB.txt 512 4 1 0 4 0 0
opening file with O_DIRECT
BLAKE3 hash: 90e7144c7a091d505102e433fb4f2160d1d56d7f5b39291206819e5648c1e639
Number of requests in-flight:
3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 0, 0,
Num records: 1042
real 0m0.431s
user 0m0.414s
sys 0m0.016s
I have attached the instrumented version below:
// This is the instrumented version of liburing_b3sum_singlethread.
/* SPDX-License-Identifier: MIT */
/*
* Compile with: gcc -Wall -O3 -D_GNU_SOURCE liburing_b3sum_singlethread_instrumented.c -luring libblake3.a -o liburing_b3sum_singlethread_instrumented
* For an explanation of how this code works, see my article/blog post: https://1f604.com/b3sum
*
* This program is a modified version of the liburing cp program from Shuveb Hussain's io_uring tutorial.
* Original source code here: https://github.com/axboe/liburing/blob/master/examples/io_uring-cp.c
* The modifications were made by 1f604.
*
* The official io_uring documentation can be seen here:
* - https://kernel.dk/io_uring.pdf
* - https://kernel-recipes.org/en/2022/wp-content/uploads/2022/06/axboe-kr2022-1.pdf
*
* Acronyms: SQ = submission queue, SQE = submission queue entry, CQ = completion queue, CQE = completion queue event
*/
#include "dependencies/rust-blake3-1.3.1/c/blake3.h"
#include "liburing.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <assert.h>
#include <sys/ioctl.h>
// Instrumentation
static int in_flight_count[9000];
static unsigned long num_unfinished_requests = 0;
static int consume_idx = 0;
/* Constants */
static const int ALIGNMENT = 4 * 1024; // Needed only because O_DIRECT requires aligned memory
/* ===============================================
* ========== Start of global variables ==========
* ===============================================
* Declared static because they are only supposed to be visible within this .c file.
*
* --- Command line options ---
* The following variables are set by the user from the command line.
*/
static int g_queuedepth; /* This variable is not really the queue depth, but is more accurately described as
* "the limit on the number of incomplete requests". Allow me to explain.
* io_uring allows you to have more requests in-flight than the size of your submission
* (and completion) queues. How is this possible? Well, when you call io_uring_submit,
* normally it will submit ALL of the requests in the submission queue, which means that
* when the call returns, your submission queue is now empty, even though the requests
* are still "in-flight" and haven't been completed yet!
* In earlier kernels, you could overflow the completion queue because of this.
* Thus it says in the official io_uring documentation (https://kernel.dk/io_uring.pdf):
* Since the sqe lifetime is only that of the actual submission of it, it's possible
* for the application to drive a higher pending request count than the SQ ring size
* would indicate. The application must take care not to do so, or it could risk
* overflowing the CQ ring.
* That is to say, the official documentation recommended that applications should ensure
* that the number of in-flight requests does not exceed the size of the submission queue.
* This g_queuedepth variable is therefore a limit on the total number of "incomplete"
* requests, which is the number of requests on the submission queue plus the number of
* requests that are still "in flight".
* See num_unfinished_requests for details on how this is implemented. */
static int g_use_o_direct; // whether to use O_DIRECT
static int g_process_in_inner_loop; // whether to process the data inside the inner loop
static int g_use_iosqe_io_drain; // whether to issue requests with the IOSQE_IO_DRAIN flag
static int g_use_iosqe_io_link; // whether to issue requests with the IOSQE_IO_LINK flag
//static int g_use_ioring_setup_iopoll; // when I enable either IORING_SETUP_SQPOLL or IORING_SETUP_IOPOLL, on my current system,
//static int g_use_ioring_setup_sqpoll; // it turns my process into an unkillable zombie that uses 100% CPU that never terminates.
// when I was using encrypted LVM, it just gave me error: Operation not supported.
// I decided to not allow users to enable these options because I didn't want them
// to accidentally launch an unkillable never-ending zombie process that uses 100% CPU.
// I observed this problem in fio too when I enabled --hipri on fio, it also turned into
// an unkillable never-ending zombie process that uses 100% CPU.
static size_t g_blocksize; // This is the size of each buffer in the ringbuf, in bytes.
// It is also the size of each read from the file.
static size_t g_numbufs; // This is the number of buffers in the ringbuf.
/* --- Non-command line argument global variables --- */
blake3_hasher g_hasher;
blake3_hasher g_hasher2;
static int g_filedescriptor; // This is the file descriptor of the file we're hashing.
static size_t g_filesize; // This will be filled in by the function that gets the file size.
static size_t g_num_blocks_in_file; // The number of blocks in the file, where each block is g_blocksize bytes.
// This will be calculated by a ceiling division of filesize by blocksize.
static size_t g_size_of_last_block; // The size of the last block in the file. See calculate_numblocks_and_size_of_last_block.
static int producer_head = 0; // Position of the "producer head". see explanation in my article/blog post
static int consumer_head = 0; // Position of the "consumer head". see explanation in my article/blog post
enum ItemState { // describes the state of a cell in the ring buffer array ringbuf, see my article/blog post for detailed explanation
AVAILABLE_FOR_CONSUMPTION, // consumption and processing in the context of this program refers to hashing
ALREADY_CONSUMED,
REQUESTED_BUT_NOT_YET_COMPLETED,
};
struct my_custom_data { // This is the user_data associated with read requests, which are placed on the submission ring.
// In applications using io_uring, the user_data struct is generally used to identify which request a
// completion is for. In the context of this program, this structure is used both to identify which
// block of the file the read syscall had just read, as well as for the producer and consumer to
// communicate with each other, since it holds the cell state.
// This can be thought of as a "cell" in the ring buffer, since it holds the state of the cell as well
// as a pointer to the data (i.e. a block read from the file) that is "in" the cell.
// Note that according to the official io_uring documentation, the user_data struct only needs to be
// valid until the submit is done, not until completion. Basically, when you submit, the kernel makes
// a copy of user_data and returns it to you with the CQE (completion queue entry).
unsigned char* buf_addr; // Pointer to the buffer where the read syscall is to place the bytes from the file into.
size_t nbytes_expected; // The number of bytes we expect the read syscall to return. This can be smaller than the size of the buffer
// because the last block of the file can be smaller than the other blocks.
//size_t nbytes_to_request; // The number of bytes to request. This is always g_blocksize. I made this decision because O_DIRECT requires
// nbytes to be a multiple of filesystem block size, and it's simpler to always just request g_blocksize.
off_t offset_of_block_in_file; // The offset of the block in the file that we want the read syscall to place into the memory location
// pointed to by buf_addr.
enum ItemState state; // Describes whether the item is available to be hashed, already hashed, or requested but not yet available for hashing.
int ringbuf_index; // The slot in g_ringbuf where this "cell" belongs.
// I added this because once we submit a request on submission queue, we lose track of it.
// When we get back a completion, we need an identifier to know which request the completion is for.
// Alternatively, we could use something to map the buf_addr to the ringbuf_index, but this is just simpler.
};
struct my_custom_data* g_ringbuf; // This is a pointer to an array of my_custom_data structs. These my_custom_data structs can be thought of as the
// "cells" in the ring buffer (each struct contains the cell state), thus the array that this points to can be
// thought of as the "ring buffer" referred to in my article/blog post, so read that to understand how this is used.
// See the allocate_ringbuf function for details on how and where the memory for the ring buffer is allocated.
/* ===============================================
* =========== End of global variables ===========
* ===============================================*/
static int setup_io_uring_context(unsigned entries, struct io_uring *ring)
{
int rc;
int flags = 0;
rc = io_uring_queue_init(entries, ring, flags);
if (rc < 0) {
fprintf(stderr, "queue_init: %s\n", strerror(-rc));
return -1;
}
return 0;
}
static int get_file_size(int fd, size_t *size)
{
struct stat st;
if (fstat(fd, &st) < 0)
return -1;
if (S_ISREG(st.st_mode)) {
*size = st.st_size;
return 0;
} else if (S_ISBLK(st.st_mode)) {
unsigned long long bytes;
if (ioctl(fd, BLKGETSIZE64, &bytes) != 0)
return -1;
*size = bytes;
return 0;
}
return -1;
}
static void add_read_request_to_submission_queue(struct io_uring *ring, size_t expected_return_size, off_t fileoffset_to_request)
{
assert(fileoffset_to_request % g_blocksize == 0);
int block_number = fileoffset_to_request / g_blocksize; // the number of the block in the file
/* We do a modulo to map the file block number to the index in the ringbuf
e.g. if ring buf_addr has 4 slots, then
file block 0 -> ringbuf index 0
file block 1 -> ringbuf index 1
file block 2 -> ringbuf index 2
file block 3 -> ringbuf index 3
file block 4 -> ringbuf index 0
file block 5 -> ringbuf index 1
file block 6 -> ringbuf index 2
And so on.
*/
int ringbuf_idx = block_number % g_numbufs;
struct my_custom_data* my_data = &g_ringbuf[ringbuf_idx];
assert(my_data->ringbuf_index == ringbuf_idx); // The ringbuf_index of a my_custom_data struct should never change.
my_data->offset_of_block_in_file = fileoffset_to_request;
assert (my_data->buf_addr); // We don't need to change my_data->buf_addr since we set it to point into the backing buffer at the start of the program.
my_data->nbytes_expected = expected_return_size;
my_data->state = REQUESTED_BUT_NOT_YET_COMPLETED; /* At this point:
* 1. The producer is about to send it off in a request.
* 2. The consumer shouldn't be trying to read this buffer at this point.
* So it is okay to set the state to this here.
*/
struct io_uring_sqe* sqe = io_uring_get_sqe(ring);
if (!sqe) {
puts("ERROR: FAILED TO GET SQE");
exit(1);
}
io_uring_prep_read(sqe, g_filedescriptor, my_data->buf_addr, g_blocksize, fileoffset_to_request);
// io_uring_prep_read sets sqe->flags to 0, so we need to set the flags AFTER calling it.
if (g_use_iosqe_io_drain)
sqe->flags |= IOSQE_IO_DRAIN;
if (g_use_iosqe_io_link)
sqe->flags |= IOSQE_IO_LINK;
io_uring_sqe_set_data(sqe, my_data);
}
static void increment_buffer_index(int* head) // moves the producer or consumer head forward by one position
{
*head = (*head + 1) % g_numbufs; // wrap around when we reach the end of the ringbuf.
}
static void resume_consumer() // Conceptually, this resumes the consumer "thread".
{ // As this program is single-threaded, we can think of it as cooperative multitasking.
in_flight_count[consume_idx] = num_unfinished_requests;
++consume_idx;
while (g_ringbuf[consumer_head].state == AVAILABLE_FOR_CONSUMPTION){
// Consume the item.
// The producer has already checked that nbytes_expected is the same as the amount of bytes actually returned.
// If the read syscall returned something different to nbytes_expected then the program would have terminated with an error message.
// Therefore it is okay to assume here that nbytes_expected is the same as the amount of actual data in the buffer.
blake3_hasher_update(&g_hasher, g_ringbuf[consumer_head].buf_addr, g_ringbuf[consumer_head].nbytes_expected);
// blake3_hasher_update(&g_hasher2, g_ringbuf[consumer_head].buf_addr, g_ringbuf[consumer_head].nbytes_expected);
// We have finished consuming the item, so mark it as consumed and move the consumer head to point to the next cell in the ringbuffer.
g_ringbuf[consumer_head].state = ALREADY_CONSUMED;
increment_buffer_index(&consumer_head);
}
}
static void producer_thread()
{
int rc;
unsigned long num_blocks_left_to_request = g_num_blocks_in_file;
unsigned long num_blocks_left_to_receive = g_num_blocks_in_file;
/* A brief note on how the num_unfinished_requests variable is used:
* As mentioned earlier, in io_uring it is possible to have more requests in-flight than the
* size of the completion ring. In earlier kernels this could cause the completion queue to overflow.
* In later kernels there was an option added (IORING_FEAT_NODROP) which, when enabled, means that
* if a completion event occurs and the completion queue is full, then the kernel will internally
* store the event until the completion queue has room for more entries.
* Therefore, on newer kernels, it isn't necessary, strictly speaking, for the application to limit
* the number of in-flight requests. But, since it is almost certainly the case that an application
* can submit requests at a faster rate than the system is capable of servicing them, if we don't
* have some backpressure mechanism, then the application will just keep on submitting more and more
* requests, which will eventually lead to the system running out of memory.
* Setting a hard limit on the total number of in-flight requests serves as a backpressure mechanism
* to prevent the number of requests buffered in the kernel from growing without bound.
* The implementation is very simple: we increment num_unfinished_requests whenever a request is placed
* onto the submission queue, and decrement it whenever an entry is removed from the completion queue.
* Once num_unfinished_requests hits the limit that we set, then we cannot issue any more requests
* until we receive more completions, therefore the number of new completions that we receive is exactly
* equal to the number of new requests that we will place, thus ensuring that the number of in-flight
* requests can never exceed g_queuedepth.
*/
off_t next_file_offset_to_request = 0;
struct io_uring uring;
if (setup_io_uring_context(g_queuedepth, &uring)) {
puts("FAILED TO SET UP CONTEXT");
exit(1);
}
struct io_uring* ring = ů
while (num_blocks_left_to_receive) { // This loop consists of 3 steps:
// Step 1. Submit read requests.
// Step 2. Retrieve completions.
// Step 3. Run consumer.
/*
* Step 1: Make zero or more read requests until g_queuedepth limit is reached, or until the producer head reaches
* a cell that is not in the ALREADY_CONSUMED state (see my article/blog post for explanation).
*/
unsigned long num_unfinished_requests_prev = num_unfinished_requests; // The only purpose of this variable is to keep track of whether
// or not we added any new requests to the submission queue.
while (num_blocks_left_to_request) {
if (num_unfinished_requests >= g_queuedepth)
break;
if (g_ringbuf[producer_head].state != ALREADY_CONSUMED)
break;
/* expected_return_size is the number of bytes that we expect this read request to return.
* expected_return_size will be the block size until the last block of the file.
* when we get to the last block of the file, expected_return_size will be the size of the last
* block of the file, which is calculated in calculate_numblocks_and_size_of_last_block
*/
size_t expected_return_size = g_blocksize;
if (num_blocks_left_to_request == 1) // if we're at the last block of the file
expected_return_size = g_size_of_last_block;
add_read_request_to_submission_queue(ring, expected_return_size, next_file_offset_to_request);
next_file_offset_to_request += expected_return_size;
++num_unfinished_requests;
--num_blocks_left_to_request;
// We have added a request for the read syscall to write into the cell in the ringbuffer.
// The add_read_request_to_submission_queue has already marked it as REQUESTED_BUT_NOT_YET_COMPLETED,
// so now we just need to move the producer head to point to the next cell in the ringbuffer.
increment_buffer_index(&producer_head);
}
// If we added any read requests to the submission queue, then submit them.
if (num_unfinished_requests_prev != num_unfinished_requests) {
rc = io_uring_submit(ring);
if (rc < 0) {
fprintf(stderr, "io_uring_submit: %s\n", strerror(-rc));
exit(1);
}
}
/*
* Step 2: Remove all the items from the completion queue.
*/
bool first_iteration = 1; // On the first iteration of the loop, we wait for at least one cqe to be available,
// then remove one cqe.
// On each subsequent iteration, we try to remove one cqe without waiting.
// The loop terminates only when there are no more items left in the completion queue,
while (num_blocks_left_to_receive) { // Or when we've read in all of the blocks of the file.
struct io_uring_cqe *cqe;
if (first_iteration) { // On the first iteration we always wait until at least one cqe is available
rc = io_uring_wait_cqe(ring, &cqe); // This should always succeed and give us one cqe.
first_iteration = 0;
} else {
rc = io_uring_peek_cqe(ring, &cqe); // This will fail once there are no more items left in the completion queue.
if (rc == -EAGAIN) { // A return code of -EAGAIN means that there are no more items left in the completion queue.
break;
}
}
if (rc < 0) {
fprintf(stderr, "io_uring_peek_cqe: %s\n",
strerror(-rc));
exit(1);
}
assert(cqe);
// At this point we have a cqe, so let's see what our syscall returned.
struct my_custom_data *data = (struct my_custom_data*) io_uring_cqe_get_data(cqe);
// Check if the read syscall returned an error
if (cqe->res < 0) {
// we're not handling EAGAIN because it should never happen.
fprintf(stderr, "cqe failed: %s\n",
strerror(-cqe->res));
exit(1);
}
// Check if the read syscall returned an unexpected number of bytes.
if ((size_t)cqe->res != data->nbytes_expected) {
// We're not handling short reads because they should never happen on a disk-based filesystem.
if ((size_t)cqe->res < data->nbytes_expected) {
puts("panic: short read");
} else {
puts("panic: read returned more data than expected (wtf). Is the file changing while you're reading it??");
}
exit(1);
}
assert(data->offset_of_block_in_file % g_blocksize == 0);
// If we reach this point, then it means that there were no errors: the read syscall returned exactly what we expected.
// Since the read syscall returned, this means it has finished filling in the cell with ONE block of data from the file.
// This means that the cell can now be read by the consumer, so we need to update the cell state.
g_ringbuf[data->ringbuf_index].state = AVAILABLE_FOR_CONSUMPTION;
--num_blocks_left_to_receive; // We received ONE block of data from the file
io_uring_cqe_seen(ring, cqe); // mark the cqe as consumed, so that its slot can get reused
--num_unfinished_requests;
if (g_process_in_inner_loop)
resume_consumer();
}
/* Step 3: Run consumer. This might be thought of as handing over control to the consumer "thread". See my article/blog post. */
resume_consumer();
}
resume_consumer();
close(g_filedescriptor);
io_uring_queue_exit(ring);
// Finalize the hash. BLAKE3_OUT_LEN is the default output length, 32 bytes.
uint8_t output[BLAKE3_OUT_LEN];
uint8_t output2[BLAKE3_OUT_LEN];
blake3_hasher_finalize(&g_hasher, output, BLAKE3_OUT_LEN);
blake3_hasher_finalize(&g_hasher2, output2, BLAKE3_OUT_LEN);
// Print the hash as hexadecimal.
printf("BLAKE3 hash: ");
for (size_t i = 0; i < BLAKE3_OUT_LEN; ++i) {
printf("%02x", output[i]);
}
printf("\n");
}
static void process_cmd_line_args(int argc, char* argv[])
{
if (argc != 9) {
printf("%s: infile g_blocksize g_queuedepth g_use_o_direct g_process_in_inner_loop g_numbufs g_use_iosqe_io_drain g_use_iosqe_io_link\n", argv[0]);
exit(1);
}
g_blocksize = atoi(argv[2]) * 1024; // The command line argument is in KiBs
g_queuedepth = atoi(argv[3]);
if (g_queuedepth > 32768)
puts("Warning: io_uring queue depth limit on Kernel 6.1.0 is 32768...");
g_use_o_direct = atoi(argv[4]);
g_process_in_inner_loop = atoi(argv[5]);
g_numbufs = atoi(argv[6]);
g_use_iosqe_io_drain = atoi(argv[7]);
g_use_iosqe_io_link = atoi(argv[8]);
}
static void open_and_get_size_of_file(const char* filename)
{
if (g_use_o_direct){
g_filedescriptor = open(filename, O_RDONLY | O_DIRECT);
puts("opening file with O_DIRECT");
} else {
g_filedescriptor = open(filename, O_RDONLY);
puts("opening file without O_DIRECT");
}
if (g_filedescriptor < 0) {
perror("open file");
exit(1);
}
if (get_file_size(g_filedescriptor, &g_filesize)){
puts("Failed getting file size");
exit(1);
}
}
static void calculate_numblocks_and_size_of_last_block()
{
// this is the mathematically correct way to do ceiling division
// (assumes no integer overflow)
g_num_blocks_in_file = (g_filesize + g_blocksize - 1) / g_blocksize;
// calculate the size of the last block of the file
if (g_filesize % g_blocksize == 0)
g_size_of_last_block = g_blocksize;
else
g_size_of_last_block = g_filesize % g_blocksize;
}
static void allocate_ringbuf()
{
// We only make 2 memory allocations in this entire program and they both happen in this function.
assert(g_blocksize % ALIGNMENT == 0);
// First, we allocate the entire underlying ring buffer (which is a contiguous block of memory
// containing all the actual buffers) in a single allocation.
// This is one big piece of memory which is used to hold the actual data from the file.
// The buf_addr field in the my_custom_data struct points to a buffer within this ring buffer.
unsigned char* ptr_to_underlying_ring_buffer;
// We need aligned memory, because O_DIRECT requires it.
if (posix_memalign((void**)&ptr_to_underlying_ring_buffer, ALIGNMENT, g_blocksize * g_numbufs)) {
puts("posix_memalign failed!");
exit(1);
}
// Second, we allocate an array containing all of the my_custom_data structs.
// This is not an array of pointers, but an array holding all of the actual structs.
// All the items are the same size, which makes this easy
g_ringbuf = (struct my_custom_data*) malloc(g_numbufs * sizeof(struct my_custom_data));
// We partially initialize all of the my_custom_data structs here.
// (The other fields are initialized in the add_read_request_to_submission_queue function)
off_t cur_offset = 0;
for (int i = 0; i < g_numbufs; ++i) {
g_ringbuf[i].buf_addr = ptr_to_underlying_ring_buffer + cur_offset; // This will never change during the runtime of this program.
cur_offset += g_blocksize;
// g_ringbuf[i].bufsize = g_blocksize; // all the buffers are the same size.
g_ringbuf[i].state = ALREADY_CONSUMED; // We need to set all cells to ALREADY_CONSUMED at the start. See my article/blog post for explanation.
g_ringbuf[i].ringbuf_index = i; // This will never change during the runtime of this program.
}
}
int main(int argc, char *argv[])
{
assert(sizeof(size_t) >= 8); // we want 64 bit size_t for files larger than 4GB...
process_cmd_line_args(argc, argv); // we need to first parse the command line arguments
open_and_get_size_of_file(argv[1]);
calculate_numblocks_and_size_of_last_block();
allocate_ringbuf();
// Initialize the hasher.
blake3_hasher_init(&g_hasher);
blake3_hasher_init(&g_hasher2);
// Run the main loop
producer_thread();
puts("Number of requests in-flight:");
for (int i = 0; i < consume_idx; ++i){
printf("%d, ", in_flight_count[i]);
}
printf("\n");
printf("Num records: %d\n", consume_idx);
}
Additional Notes
What is the theoretical speed limit for any possible file hashing program on my system? To calculate this we only need to know 2 things: first, how fast a file can be read from the file system, and second, how fast the hash can be computed.
In the system that I used for testing the b3sum programs, a 1GiB file (1073741824 bytes) took a minimum of 0.302 seconds to be read from the file system (according to fio. For more details see below), thus the fastest speed that a file could be read from the file system was around 3.311GiB/s or 3.555GB/s.
To measure the speed at which the BLAKE3 hash can be computed, one can simply run the example program twice without flushing the page cache - the second, much shorter running time reflects the hashing speed, since the file was already cached in memory. On my system, a 1GiB file that was already cached in memory could be hashed in 0.252s, which is around 3.968 GiB/s or 4.26 GB/s.
Thus we know that on my system, the hashing speed is greater than the file read speed. What does this mean? Consider a simple producer-consumer implementation where the producer thread is reading the file one block at a time from the file system, and handing the blocks over to the consumer thread which then hashes each block as it comes. Since the consumer thread can consume blocks at a faster rate than the producer thread can produce them, this means that the program is bottlenecked on the producer - the program cannot finish before the producer has finished reading in all of the blocks.
Thus, the theoretical speed limit of any b3sum program on this system is 3.311GiB/s or 3.555GB/s - the speed at which a file can be read from the file system. To put it in simpler terms, it means that on my system, a 1GiB file cannot possibly be hashed in less than 0.302s.
Here’s the result of running fio on my current system (which is the system on which the benchmarks at the top of this article were done) with block size of 128k:
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=100% --io_size=1g --blocksize=128k --ioengine=io_uring --fsync=10000 --iodepth=4 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=io_uring, iodepth=4
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=3797: Mon Jul 17 19:31:29 2023
read: IOPS=27.0k, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=2, max=118, avg= 8.32, stdev= 2.03
clat (usec): min=69, max=604, avg=138.31, stdev=33.95
lat (usec): min=78, max=722, avg=146.63, stdev=34.28
clat percentiles (usec):
| 1.00th=[ 122], 5.00th=[ 128], 10.00th=[ 130], 20.00th=[ 130],
| 30.00th=[ 131], 40.00th=[ 131], 50.00th=[ 131], 60.00th=[ 131],
| 70.00th=[ 133], 80.00th=[ 133], 90.00th=[ 137], 95.00th=[ 204],
| 99.00th=[ 334], 99.50th=[ 379], 99.90th=[ 449], 99.95th=[ 482],
| 99.99th=[ 603]
lat (usec) : 100=0.02%, 250=98.27%, 500=1.68%, 750=0.02%
cpu : usr=4.64%, sys=33.77%, ctx=8150, majf=0, minf=141
IO depths : 1=0.1%, 2=0.1%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=8192,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
The result from fio depends on the blocksize and the iodepth. I found that using a block size of 512KiB on my current system gave the best results. 302ms is the lowest I ever saw from fio:
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4444: Tue Jul 25 17:39:46 2023
read: IOPS=6759, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=6, max=259, avg=17.83, stdev= 7.24
clat (usec): min=162, max=648, avg=276.04, stdev=49.54
lat (usec): min=175, max=770, avg=293.87, stdev=50.74
clat percentiles (usec):
| 1.00th=[ 251], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 262], 40.00th=[ 262], 50.00th=[ 262], 60.00th=[ 262],
| 70.00th=[ 262], 80.00th=[ 265], 90.00th=[ 330], 95.00th=[ 367],
| 99.00th=[ 529], 99.50th=[ 594], 99.90th=[ 619], 99.95th=[ 644],
| 99.99th=[ 652]
lat (usec) : 250=0.68%, 500=97.71%, 750=1.61%
cpu : usr=3.64%, sys=12.91%, ctx=2047, majf=0, minf=265
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
Disk stats (read/write):
nvme0n1: ios=1977/0, merge=0/0, ticks=481/0, in_queue=481, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4463: Tue Jul 25 17:39:47 2023
read: IOPS=6781, BW=3391MiB/s (3555MB/s)(1024MiB/302msec)
slat (usec): min=5, max=258, avg=13.00, stdev= 7.63
clat (usec): min=214, max=657, avg=281.06, stdev=49.22
lat (usec): min=234, max=767, avg=294.06, stdev=50.43
clat percentiles (usec):
| 1.00th=[ 258], 5.00th=[ 262], 10.00th=[ 265], 20.00th=[ 265],
| 30.00th=[ 265], 40.00th=[ 265], 50.00th=[ 269], 60.00th=[ 269],
| 70.00th=[ 269], 80.00th=[ 269], 90.00th=[ 334], 95.00th=[ 375],
| 99.00th=[ 537], 99.50th=[ 603], 99.90th=[ 619], 99.95th=[ 652],
| 99.99th=[ 660]
lat (usec) : 250=0.49%, 500=97.71%, 750=1.81%
cpu : usr=0.00%, sys=12.29%, ctx=2048, majf=0, minf=268
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3391MiB/s (3555MB/s), 3391MiB/s-3391MiB/s (3555MB/s-3555MB/s), io=1024MiB (1074MB), run=302-302msec
Disk stats (read/write):
nvme0n1: ios=1979/0, merge=0/0, ticks=496/0, in_queue=496, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4482: Tue Jul 25 17:39:47 2023
read: IOPS=6759, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=6, max=262, avg=18.51, stdev= 7.30
clat (usec): min=223, max=646, avg=275.47, stdev=48.93
lat (usec): min=243, max=773, avg=293.98, stdev=50.54
clat percentiles (usec):
| 1.00th=[ 251], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 262], 40.00th=[ 262], 50.00th=[ 262], 60.00th=[ 262],
| 70.00th=[ 262], 80.00th=[ 262], 90.00th=[ 326], 95.00th=[ 367],
| 99.00th=[ 529], 99.50th=[ 586], 99.90th=[ 611], 99.95th=[ 644],
| 99.99th=[ 644]
lat (usec) : 250=0.83%, 500=97.56%, 750=1.61%
cpu : usr=0.00%, sys=16.89%, ctx=2048, majf=0, minf=266
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
Disk stats (read/write):
nvme0n1: ios=1977/0, merge=0/0, ticks=480/0, in_queue=480, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4501: Tue Jul 25 17:39:48 2023
read: IOPS=6759, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=6, max=260, avg=18.08, stdev= 7.25
clat (usec): min=230, max=649, avg=275.81, stdev=49.25
lat (usec): min=251, max=769, avg=293.89, stdev=50.52
clat percentiles (usec):
| 1.00th=[ 251], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 262], 40.00th=[ 262], 50.00th=[ 262], 60.00th=[ 262],
| 70.00th=[ 262], 80.00th=[ 265], 90.00th=[ 330], 95.00th=[ 367],
| 99.00th=[ 529], 99.50th=[ 594], 99.90th=[ 619], 99.95th=[ 644],
| 99.99th=[ 652]
lat (usec) : 250=0.39%, 500=98.00%, 750=1.61%
cpu : usr=1.32%, sys=15.23%, ctx=2049, majf=0, minf=266
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
Disk stats (read/write):
nvme0n1: ios=1978/0, merge=0/0, ticks=481/0, in_queue=482, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4520: Tue Jul 25 17:39:49 2023
read: IOPS=6759, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=10, max=297, avg=31.39, stdev= 7.77
clat (usec): min=177, max=639, avg=262.32, stdev=49.90
lat (usec): min=229, max=800, avg=293.72, stdev=51.18
clat percentiles (usec):
| 1.00th=[ 237], 5.00th=[ 243], 10.00th=[ 245], 20.00th=[ 247],
| 30.00th=[ 247], 40.00th=[ 247], 50.00th=[ 247], 60.00th=[ 247],
| 70.00th=[ 247], 80.00th=[ 249], 90.00th=[ 314], 95.00th=[ 355],
| 99.00th=[ 523], 99.50th=[ 586], 99.90th=[ 603], 99.95th=[ 627],
| 99.99th=[ 644]
lat (usec) : 250=82.28%, 500=16.11%, 750=1.61%
cpu : usr=0.00%, sys=25.83%, ctx=2047, majf=0, minf=266
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
Disk stats (read/write):
nvme0n1: ios=1977/0, merge=0/0, ticks=477/0, in_queue=477, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4539: Tue Jul 25 17:39:50 2023
read: IOPS=6759, BW=3380MiB/s (3544MB/s)(1024MiB/303msec)
slat (usec): min=6, max=263, avg=18.32, stdev= 7.38
clat (usec): min=163, max=689, avg=275.59, stdev=50.07
lat (usec): min=177, max=952, avg=293.91, stdev=51.72
clat percentiles (usec):
| 1.00th=[ 251], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 260], 40.00th=[ 262], 50.00th=[ 262], 60.00th=[ 262],
| 70.00th=[ 262], 80.00th=[ 265], 90.00th=[ 326], 95.00th=[ 367],
| 99.00th=[ 545], 99.50th=[ 594], 99.90th=[ 644], 99.95th=[ 644],
| 99.99th=[ 693]
lat (usec) : 250=0.63%, 500=97.75%, 750=1.61%
cpu : usr=0.00%, sys=16.89%, ctx=2047, majf=0, minf=267
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3380MiB/s (3544MB/s), 3380MiB/s-3380MiB/s (3544MB/s-3544MB/s), io=1024MiB (1074MB), run=303-303msec
Disk stats (read/write):
nvme0n1: ios=1978/0, merge=0/0, ticks=482/0, in_queue=482, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4558: Tue Jul 25 17:39:51 2023
read: IOPS=6781, BW=3391MiB/s (3555MB/s)(1024MiB/302msec)
slat (usec): min=6, max=260, avg=17.98, stdev= 7.13
clat (usec): min=180, max=745, avg=275.94, stdev=50.17
lat (usec): min=194, max=1006, avg=293.92, stdev=52.07
clat percentiles (usec):
| 1.00th=[ 251], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 262], 40.00th=[ 262], 50.00th=[ 262], 60.00th=[ 262],
| 70.00th=[ 262], 80.00th=[ 265], 90.00th=[ 326], 95.00th=[ 367],
| 99.00th=[ 545], 99.50th=[ 594], 99.90th=[ 644], 99.95th=[ 660],
| 99.99th=[ 742]
lat (usec) : 250=0.63%, 500=97.61%, 750=1.76%
cpu : usr=2.66%, sys=13.62%, ctx=2048, majf=0, minf=268
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3391MiB/s (3555MB/s), 3391MiB/s-3391MiB/s (3555MB/s-3555MB/s), io=1024MiB (1074MB), run=302-302msec
Disk stats (read/write):
nvme0n1: ios=1978/0, merge=0/0, ticks=480/0, in_queue=481, util=61.04%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=1g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
TEST: (groupid=0, jobs=1): err= 0: pid=4577: Tue Jul 25 17:39:52 2023
read: IOPS=6781, BW=3391MiB/s (3555MB/s)(1024MiB/302msec)
slat (usec): min=6, max=262, avg=19.10, stdev= 7.35
clat (usec): min=218, max=654, avg=274.66, stdev=49.05
lat (usec): min=251, max=807, avg=293.75, stdev=50.54
clat percentiles (usec):
| 1.00th=[ 249], 5.00th=[ 258], 10.00th=[ 260], 20.00th=[ 260],
| 30.00th=[ 260], 40.00th=[ 260], 50.00th=[ 260], 60.00th=[ 260],
| 70.00th=[ 262], 80.00th=[ 262], 90.00th=[ 326], 95.00th=[ 367],
| 99.00th=[ 537], 99.50th=[ 586], 99.90th=[ 611], 99.95th=[ 644],
| 99.99th=[ 652]
lat (usec) : 250=1.03%, 500=97.41%, 750=1.56%
cpu : usr=0.00%, sys=17.61%, ctx=2048, majf=0, minf=268
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=2048,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3391MiB/s (3555MB/s), 3391MiB/s-3391MiB/s (3555MB/s-3555MB/s), io=1024MiB (1074MB), run=302-302msec
Disk stats (read/write):
nvme0n1: ios=1979/0, merge=0/0, ticks=480/0, in_queue=481, util=61.04%
Here are the results from setting the io size to 10GiB, somehow this made it slower.
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=32
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3382MiB/s][r=3382 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3014: Tue Jul 25 00:02:27 2023
read: IOPS=3370, BW=3371MiB/s (3534MB/s)(10.0GiB/3038msec)
slat (usec): min=6, max=1227, avg=19.20, stdev=15.52
clat (usec): min=578, max=22014, avg=9451.40, stdev=1298.66
lat (usec): min=601, max=22032, avg=9470.60, stdev=1296.89
clat percentiles (usec):
| 1.00th=[ 5997], 5.00th=[ 9110], 10.00th=[ 9110], 20.00th=[ 9110],
| 30.00th=[ 9110], 40.00th=[ 9241], 50.00th=[ 9241], 60.00th=[ 9503],
| 70.00th=[ 9634], 80.00th=[ 9634], 90.00th=[ 9634], 95.00th=[ 9896],
| 99.00th=[16319], 99.50th=[19268], 99.90th=[21365], 99.95th=[21627],
| 99.99th=[21890]
bw ( MiB/s): min= 3360, max= 3406, per=100.00%, avg=3378.00, stdev=16.15, samples=6
iops : min= 3360, max= 3406, avg=3378.00, stdev=16.15, samples=6
lat (usec) : 750=0.04%, 1000=0.04%
lat (msec) : 2=0.16%, 4=0.39%, 10=95.45%, 20=3.54%, 50=0.39%
cpu : usr=0.59%, sys=8.23%, ctx=10225, majf=0, minf=30
IO depths : 1=0.1%, 2=0.1%, 4=0.2%, 8=0.4%, 16=0.8%, 32=98.5%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=3371MiB/s (3534MB/s), 3371MiB/s-3371MiB/s (3534MB/s-3534MB/s), io=10.0GiB (10.7GB), run=3038-3038msec
Disk stats (read/write):
nvme0n1: ios=39088/0, merge=30/0, ticks=361238/0, in_queue=361238, util=96.76%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=4 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=4
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3386MiB/s][r=3386 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3033: Tue Jul 25 00:02:39 2023
read: IOPS=3375, BW=3375MiB/s (3539MB/s)(10.0GiB/3034msec)
slat (usec): min=6, max=582, avg=30.97, stdev=13.43
clat (usec): min=514, max=2248, avg=1152.31, stdev=134.69
lat (usec): min=570, max=2265, avg=1183.28, stdev=134.35
clat percentiles (usec):
| 1.00th=[ 1074], 5.00th=[ 1074], 10.00th=[ 1074], 20.00th=[ 1090],
| 30.00th=[ 1090], 40.00th=[ 1090], 50.00th=[ 1106], 60.00th=[ 1106],
| 70.00th=[ 1156], 80.00th=[ 1188], 90.00th=[ 1221], 95.00th=[ 1467],
| 99.00th=[ 1778], 99.50th=[ 1909], 99.90th=[ 2008], 99.95th=[ 2057],
| 99.99th=[ 2245]
bw ( MiB/s): min= 3364, max= 3412, per=100.00%, avg=3381.33, stdev=17.00, samples=6
iops : min= 3364, max= 3412, avg=3381.33, stdev=17.00, samples=6
lat (usec) : 750=0.05%, 1000=0.08%
lat (msec) : 2=99.74%, 4=0.14%
cpu : usr=0.76%, sys=12.30%, ctx=10240, majf=0, minf=523
IO depths : 1=0.1%, 2=0.1%, 4=99.9%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
READ: bw=3375MiB/s (3539MB/s), 3375MiB/s-3375MiB/s (3539MB/s-3539MB/s), io=10.0GiB (10.7GB), run=3034-3034msec
Disk stats (read/write):
nvme0n1: ios=39137/0, merge=0/0, ticks=40995/0, in_queue=40995, util=96.76%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=128k --ioengine=io_uring --fsync=10000 --iodepth=4 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=io_uring, iodepth=4
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3383MiB/s][r=27.1k IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3071: Tue Jul 25 00:02:57 2023
read: IOPS=27.0k, BW=3373MiB/s (3537MB/s)(10.0GiB/3036msec)
slat (usec): min=3, max=120, avg=10.17, stdev= 1.31
clat (usec): min=81, max=2362, avg=137.30, stdev=37.04
lat (usec): min=100, max=2372, avg=147.47, stdev=37.04
clat percentiles (usec):
| 1.00th=[ 120], 5.00th=[ 126], 10.00th=[ 128], 20.00th=[ 129],
| 30.00th=[ 129], 40.00th=[ 129], 50.00th=[ 129], 60.00th=[ 130],
| 70.00th=[ 130], 80.00th=[ 130], 90.00th=[ 137], 95.00th=[ 204],
| 99.00th=[ 306], 99.50th=[ 359], 99.90th=[ 445], 99.95th=[ 478],
| 99.99th=[ 685]
bw ( MiB/s): min= 3362, max= 3407, per=100.00%, avg=3378.79, stdev=17.59, samples=6
iops : min=26896, max=27258, avg=27030.33, stdev=140.69, samples=6
lat (usec) : 100=0.01%, 250=98.11%, 500=1.86%, 750=0.02%
lat (msec) : 4=0.01%
cpu : usr=5.77%, sys=36.54%, ctx=81525, majf=0, minf=138
IO depths : 1=0.1%, 2=0.1%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=81920,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
READ: bw=3373MiB/s (3537MB/s), 3373MiB/s-3373MiB/s (3537MB/s-3537MB/s), io=10.0GiB (10.7GB), run=3036-3036msec
Disk stats (read/write):
nvme0n1: ios=78208/2, merge=0/1, ticks=10769/0, in_queue=10770, util=97.03%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=256k --ioengine=io_uring --fsync=10000 --iodepth=4 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 256KiB-256KiB, (W) 256KiB-256KiB, (T) 256KiB-256KiB, ioengine=io_uring, iodepth=4
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3387MiB/s][r=13.5k IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3090: Tue Jul 25 00:03:06 2023
read: IOPS=13.5k, BW=3377MiB/s (3541MB/s)(10.0GiB/3032msec)
slat (usec): min=4, max=181, avg=14.10, stdev= 2.00
clat (usec): min=186, max=908, avg=281.24, stdev=49.54
lat (usec): min=221, max=923, avg=295.33, stdev=49.53
clat percentiles (usec):
| 1.00th=[ 255], 5.00th=[ 262], 10.00th=[ 265], 20.00th=[ 265],
| 30.00th=[ 265], 40.00th=[ 265], 50.00th=[ 265], 60.00th=[ 265],
| 70.00th=[ 265], 80.00th=[ 269], 90.00th=[ 343], 95.00th=[ 375],
| 99.00th=[ 506], 99.50th=[ 570], 99.90th=[ 644], 99.95th=[ 717],
| 99.99th=[ 906]
bw ( MiB/s): min= 3365, max= 3410, per=100.00%, avg=3383.04, stdev=15.92, samples=6
iops : min=13460, max=13642, avg=13532.00, stdev=63.66, samples=6
lat (usec) : 250=0.35%, 500=98.51%, 750=1.09%, 1000=0.04%
cpu : usr=1.29%, sys=25.87%, ctx=40940, majf=0, minf=267
IO depths : 1=0.1%, 2=0.1%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=40960,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
READ: bw=3377MiB/s (3541MB/s), 3377MiB/s-3377MiB/s (3541MB/s-3541MB/s), io=10.0GiB (10.7GB), run=3032-3032msec
Disk stats (read/write):
nvme0n1: ios=39157/2, merge=0/1, ticks=11087/0, in_queue=11088, util=96.90%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=4 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=4
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3384MiB/s][r=6768 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3109: Tue Jul 25 00:03:14 2023
read: IOPS=6743, BW=3372MiB/s (3536MB/s)(10.0GiB/3037msec)
slat (usec): min=4, max=401, avg=11.26, stdev= 2.87
clat (usec): min=199, max=1699, avg=580.70, stdev=84.16
lat (usec): min=250, max=2043, avg=591.96, stdev=84.45
clat percentiles (usec):
| 1.00th=[ 537], 5.00th=[ 545], 10.00th=[ 545], 20.00th=[ 545],
| 30.00th=[ 545], 40.00th=[ 545], 50.00th=[ 545], 60.00th=[ 545],
| 70.00th=[ 545], 80.00th=[ 611], 90.00th=[ 660], 95.00th=[ 734],
| 99.00th=[ 963], 99.50th=[ 988], 99.90th=[ 1156], 99.95th=[ 1287],
| 99.99th=[ 1680]
bw ( MiB/s): min= 3362, max= 3404, per=100.00%, avg=3377.33, stdev=15.27, samples=6
iops : min= 6724, max= 6808, avg=6754.67, stdev=30.53, samples=6
lat (usec) : 250=0.01%, 500=0.03%, 750=95.28%, 1000=4.30%
lat (msec) : 2=0.38%
cpu : usr=1.02%, sys=11.20%, ctx=20478, majf=0, minf=14
IO depths : 1=0.1%, 2=0.1%, 4=99.9%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=4
Run status group 0 (all jobs):
READ: bw=3372MiB/s (3536MB/s), 3372MiB/s-3372MiB/s (3536MB/s-3536MB/s), io=10.0GiB (10.7GB), run=3037-3037msec
Disk stats (read/write):
nvme0n1: ios=39091/2, merge=0/1, ticks=21153/3, in_queue=21158, util=96.76%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3388MiB/s][r=6776 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3128: Tue Jul 25 00:03:24 2023
read: IOPS=6756, BW=3378MiB/s (3543MB/s)(10.0GiB/3031msec)
slat (usec): min=9, max=311, avg=29.94, stdev= 3.30
clat (usec): min=198, max=892, avg=264.98, stdev=50.38
lat (usec): min=234, max=922, avg=294.93, stdev=50.66
clat percentiles (usec):
| 1.00th=[ 239], 5.00th=[ 245], 10.00th=[ 247], 20.00th=[ 247],
| 30.00th=[ 249], 40.00th=[ 249], 50.00th=[ 249], 60.00th=[ 251],
| 70.00th=[ 251], 80.00th=[ 251], 90.00th=[ 322], 95.00th=[ 359],
| 99.00th=[ 510], 99.50th=[ 570], 99.90th=[ 652], 99.95th=[ 742],
| 99.99th=[ 889]
bw ( MiB/s): min= 3367, max= 3413, per=100.00%, avg=3384.83, stdev=15.96, samples=6
iops : min= 6734, max= 6826, avg=6769.67, stdev=31.91, samples=6
lat (usec) : 250=61.26%, 500=37.62%, 750=1.06%, 1000=0.05%
cpu : usr=0.76%, sys=24.09%, ctx=20480, majf=0, minf=267
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=3378MiB/s (3543MB/s), 3378MiB/s-3378MiB/s (3543MB/s-3543MB/s), io=10.0GiB (10.7GB), run=3031-3031msec
Disk stats (read/write):
nvme0n1: ios=39179/0, merge=0/0, ticks=9334/0, in_queue=9334, util=96.90%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=512k --ioengine=io_uring --fsync=10000 --iodepth=2 --direct=0 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=io_uring, iodepth=2
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=1795MiB/s][r=3590 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3147: Tue Jul 25 00:03:34 2023
read: IOPS=3685, BW=1843MiB/s (1932MB/s)(10.0GiB/5557msec)
slat (usec): min=28, max=499, avg=74.93, stdev=74.14
clat (usec): min=30, max=4387, avg=434.37, stdev=184.91
lat (usec): min=229, max=4499, avg=509.29, stdev=147.50
clat percentiles (usec):
| 1.00th=[ 137], 5.00th=[ 200], 10.00th=[ 204], 20.00th=[ 210],
| 30.00th=[ 306], 40.00th=[ 314], 50.00th=[ 461], 60.00th=[ 545],
| 70.00th=[ 570], 80.00th=[ 635], 90.00th=[ 660], 95.00th=[ 660],
| 99.00th=[ 725], 99.50th=[ 824], 99.90th=[ 848], 99.95th=[ 848],
| 99.99th=[ 906]
bw ( MiB/s): min= 1643, max= 1962, per=99.97%, avg=1842.19, stdev=143.95, samples=11
iops : min= 3286, max= 3924, avg=3684.36, stdev=287.89, samples=11
lat (usec) : 50=0.17%, 100=0.01%, 250=23.12%, 500=27.00%, 750=48.97%
lat (usec) : 1000=0.72%
lat (msec) : 10=0.01%
cpu : usr=0.29%, sys=80.89%, ctx=26899, majf=0, minf=266
IO depths : 1=0.1%, 2=100.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=2
Run status group 0 (all jobs):
READ: bw=1843MiB/s (1932MB/s), 1843MiB/s-1843MiB/s (1932MB/s-1932MB/s), io=10.0GiB (10.7GB), run=5557-5557msec
Disk stats (read/write):
nvme0n1: ios=39591/3, merge=0/1, ticks=7997/1, in_queue=7998, util=92.45%
I tried other block sizes and queue depths too. I tried block sizes 64k, 128k, 256k, 512k, 1024k, and queue depths 2, 4, 8, 16, 32, 64, but it was never faster than 302ms. It seems that for reading 1Gib file, 512k block size with queue depth of 2 was the fastest. I also tried setting the --nonvectored to 0 and then 1, didn’t make a difference. The running time was the same. This suggests that read and readv are the same in terms of performance …
nonvectored=int : [io_uring] [io_uring_cmd]
With this option, fio will use non-vectored read/write commands, where address must contain the address directly. Default is -1.
I also tried it with and without --fixedbufs and it also didn’t make any difference.
I also tried --registerfiles and --sqthread_poll and that didn’t make any difference either. Attempting to use --hipri created an unkillable never-ending zombie process that uses 100% CPU - I’m pretty sure it’s because of IORING_SETUP_IOPOLL, because when I enabled IORING_SETUP_IOPOLL in my program the same thing happened.
Interestingly, my liburing_b3sum_singlethread program is able to process a 10GiB file in only 2.896 seconds, even though cat to /dev/null takes longer than that:
$ echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ./liburing_b3sum_singlethread 10GB.txt 512 8 1 0 20 0 0
opening file with O_DIRECT
BLAKE3 hash: 65f593d91b9301369724bb8e0f4da385baf46c73a5fb0ac996a5d5d714028ff6
real 0m2.896s
user 0m2.187s
sys 0m0.150s
$ echo 1 > /proc/sys/vm/drop_caches; sleep 1; time cat 10GB.txt > /dev/null
real 0m2.900s
user 0m0.013s
sys 0m1.844s
Note that these numbers are different from the numbers presented at the top of this article. I think my system, for some reason unknown to me, fluctuates in performance, so sometimes it is faster and sometimes it is slower than usual, but when running comparisons I always run the programs in the same time period so that this fluctuation doesn’t affect the rankings.
Impact of LVM Encryption
I actually did most of the development for this project on my previous system, which was using LVM encryption. Later, I reinstalled Debian with non-encrypted ext4, and that’s my current system. So the hardware and OS is exactly the same, the only significant difference is that my old system was using LVM encryption and my current system is not.
Here’s the performance of cat and dd into /dev/null on my old system (which was using LVM encryption):
$ echo 1 > /proc/sys/vm/drop_caches
$ time cat 1GB.txt > /dev/null
real 0m0.540s
user 0m0.000s
sys 0m0.182s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=8K
131072+0 records in
131072+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.661612 s, 1.6 GB/s
real 0m0.664s
user 0m0.004s
sys 0m0.226s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=16K
65536+0 records in
65536+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.581368 s, 1.8 GB/s
real 0m0.585s
user 0m0.014s
sys 0m0.196s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=32K
32768+0 records in
32768+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.574081 s, 1.9 GB/s
real 0m0.577s
user 0m0.004s
sys 0m0.198s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=64K
16384+0 records in
16384+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.574562 s, 1.9 GB/s
real 0m0.577s
user 0m0.000s
sys 0m0.198s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=128K
8192+0 records in
8192+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.563443 s, 1.9 GB/s
real 0m0.566s
user 0m0.004s
sys 0m0.195s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=256K
4096+0 records in
4096+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.58437 s, 1.8 GB/s
real 0m0.587s
user 0m0.000s
sys 0m0.190s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=4M
256+0 records in
256+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.590212 s, 1.8 GB/s
real 0m0.593s
user 0m0.000s
sys 0m0.184s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=32M
32+0 records in
32+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.605234 s, 1.8 GB/s
real 0m0.608s
user 0m0.000s
sys 0m0.230s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=64M
16+0 records in
16+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.627107 s, 1.7 GB/s
real 0m0.630s
user 0m0.000s
sys 0m0.232s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=64K iflag=direct
16384+0 records in
16384+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.09124 s, 513 MB/s
real 0m2.093s
user 0m0.000s
sys 0m0.200s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=512M iflag=direct
2+0 records in
2+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.648582 s, 1.7 GB/s
real 0m0.652s
user 0m0.000s
sys 0m0.061s
$ echo 1 > /proc/sys/vm/drop_caches
$ time dd if=1GB.txt of=/dev/null bs=1G iflag=direct
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.539423 s, 2.0 GB/s
real 0m0.544s
user 0m0.004s
sys 0m0.102s
And here are the results from dd on my current machine:
| Command | Min | Median | Max |
|---|---|---|---|
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=8K | ./example_64K |
0.363s | 0.3725s | 0.381s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=8K | ./example_2M |
0.362s | 0.37s | 0.384s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=16K | ./example_64K |
0.35s | 0.3555s | 0.361s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=16K | ./example_2M |
0.346s | 0.353s | 0.357s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=32K | ./example_64K |
0.333s | 0.341s | 0.349s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=32K | ./example_2M |
0.337s | 0.346s | 0.358s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K | ./example_64K |
0.332s | 0.3385s | 0.342s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K | ./example_2M |
0.335s | 0.337s | 0.345s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=128K | ./example_64K |
0.351s | 0.3675s | 0.371s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=128K | ./example_2M |
0.344s | 0.357s | 0.505s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=256K | ./example_64K |
0.532s | 0.55s | 0.556s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=256K | ./example_2M |
0.53s | 0.547s | 0.723s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M | ./example_64K |
0.542s | 0.545s | 0.548s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M | ./example_2M |
0.542s | 0.5445s | 0.548s |
The above shows that the optimal bs for dd on my system is 64KiB. To make sure that this wasn’t because the example program was reading 64KiB at a time, I made another version of the example program that read 2M at a time (it’s simple, just change the 65536 in the example.c source code to 2 * 1024 * 1024). Their performance (see table above) was identical across all block sizes, which leads me to think that makes absolutely no difference.
The important point here to note is that the optimal block size for dd was 64KiB. Larger block sizes were slower. Here are the results with O_DIRECT on my current system:
| Command | Min | Median | Max |
|---|---|---|---|
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=8K iflag=direct | ./example_64K |
1.334s | 1.343s | 1.475s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=16K iflag=direct | ./example_64K |
0.924s | 0.927s | 0.984s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=32K iflag=direct | ./example_64K |
0.687s | 0.721s | 0.721s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K iflag=direct | ./example_64K |
0.555s | 0.555s | 0.56s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=64K iflag=direct oflag=direct | ./example_64K |
0.561s | 0.567s | 0.573s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=128K iflag=direct | ./example_64K |
0.56s | 0.5745s | 0.591s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=256K iflag=direct | ./example_64K |
0.572s | 0.573s | 0.574s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=512K iflag=direct | ./example_64K |
0.546s | 0.551s | 0.552s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=1M iflag=direct | ./example_64K |
0.553s | 0.556s | 0.557s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M iflag=direct | ./example_64K |
0.576s | 0.5865s | 0.594s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M iflag=direct | ./example_2M |
0.582s | 0.583s | 0.583s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=128M iflag=direct | ./example_64K |
0.565s | 0.579s | 0.585s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=1G iflag=direct | ./example_64K |
0.557s | 0.5605s | 0.564s |
echo 1 > /proc/sys/vm/drop_caches; sleep 1; time dd if=1GB.txt bs=2M iflag=direct oflag=direct | ./example_2M |
0.745s | 0.754s | 0.755s |
Interestingly, 64K O_DIRECT was significantly slower on my old system vs the current system. Also, the optimal block size when using O_DIRECT is significantly larger than when not using O_DIRECT. This is a recurring theme - I also found it to be be true for the non-io_uring multithreaded program, as well as for the io_uring version. Also interestingly, dd with O_DIRECT is significantly slower than dd without O_DIRECT. I also thought it was interesting that when using dd to pipe data into my program, a bs of 64KiB was optimal, but when using dd to pipe data into /dev/null, a larger bs of 2M was optimal. It is also interesting to note that cat was able to pipe data into /dev/null at the maximum possible speed, despite using a 128KiB buffer size (when I used dd with bs=128KiB, it could not reach the max speed…).
Anyway here were the results from fio on my old system:
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=32
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3522MiB/s][r=3522 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=39134: Tue Jul 11 10:51:55 2023
read: IOPS=3505, BW=3506MiB/s (3676MB/s)(10.0GiB/2921msec)
Run status group 0 (all jobs):
READ: bw=3506MiB/s (3676MB/s), 3506MiB/s-3506MiB/s (3676MB/s-3676MB/s), io=10.0GiB (10.7GB), run=2921-2921msec
Here are the results I’m getting on my current system:
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=32
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3374MiB/s][r=3374 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=1160: Mon Jul 17 17:27:35 2023
read: IOPS=3363, BW=3364MiB/s (3527MB/s)(10.0GiB/3044msec)
Run status group 0 (all jobs):
READ: bw=3364MiB/s (3527MB/s), 3364MiB/s-3364MiB/s (3527MB/s-3527MB/s), io=10.0GiB (10.7GB), run=3044-3044msec
Interestingly, the io_uring version of my program was actually almost twice as fast as cat into /dev/null on my old system which was using LVM encryption. Yes, I flushed the page cache before timing it. But on my current, non-encrypted system, the io_uring version and cat to /dev/null are almost the same speed. My guess is that encryption was adding latency, which I was able to mitigate by having multiple requests in flight at a time using io_uring, but the cat program can’t do that since it’s using synchronous reads, so the previous read has to return before the next one can begin. That’s just my guess though, haven’t verified it. But it would also explain why fio using io_uring was faster than cat on my old system.
But that doesn’t explain why fio was faster on my old system than it is on my current system. For that I have 2 guesses:
- My SSD somehow slowed down. Maybe I need to TRIM?
- My software is somehow worse. Maybe encrypted disk was faster because it was using LVM?
I think first guess is highly unlikely. I had been using the SSD with plenty of testing, and was getting consistent speed readings from fio. Second guess seems more probable, see: https://lkml.org/lkml/2010/5/7/223
More details from fio while I was using disk encryption:
The version fio I used was 3.33
Here is the command I used:
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=mmap --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
Anyway, here are the numbers I got on my machine:
sync (read): READ: bw=1313MiB/s (1377MB/s), 1313MiB/s-1313MiB/s (1377MB/s-1377MB/s), io=10.0GiB (10.7GB), run=7798-7798msec
psync (pread): READ: bw=1316MiB/s (1380MB/s), 1316MiB/s-1316MiB/s (1380MB/s-1380MB/s), io=10.0GiB (10.7GB), run=7783-7783msec
vsync (readv): READ: bw=1295MiB/s (1357MB/s), 1295MiB/s-1295MiB/s (1357MB/s-1357MB/s), io=2017MiB (2115MB), run=1558-1558msec
pvsync (preadv): READ: bw=1332MiB/s (1397MB/s), 1332MiB/s-1332MiB/s (1397MB/s-1397MB/s), io=10.0GiB (10.7GB), run=7688-7688msec
pvsync2 (preadv2): READ: bw=1304MiB/s (1368MB/s), 1304MiB/s-1304MiB/s (1368MB/s-1368MB/s), io=10.0GiB (10.7GB), run=7851-7851msec
io_uring: READ: bw=3501MiB/s (3671MB/s), 3501MiB/s-3501MiB/s (3671MB/s-3671MB/s), io=10.0GiB (10.7GB), run=2925-2925msec
libaio: READ: bw=3518MiB/s (3689MB/s), 3518MiB/s-3518MiB/s (3689MB/s-3689MB/s), io=10.0GiB (10.7GB), run=2911-2911msec
posixaio (aio_read): READ: bw=3518MiB/s (3689MB/s), 3518MiB/s-3518MiB/s (3689MB/s-3689MB/s), io=10.0GiB (10.7GB), run=2911-2911msec
mmap: READ: bw=664MiB/s (696MB/s), 664MiB/s-664MiB/s (696MB/s-696MB/s), io=10.0GiB (10.7GB), run=15431-15431msec
splice (splice and vmsplice): READ: bw=879MiB/s (921MB/s), 879MiB/s-879MiB/s (921MB/s-921MB/s), io=10.0GiB (10.7GB), run=11653-11653msec
Note that 3.5GB/s is the read speed limit of my NVME drive as advertised by the manufacturer and as verified by third party tests (that I found online), so I am pretty confident that the results given by io_uring, libaio and posix aio were hitting the physical limit of my storage device.
Further Notes
Based on some online reading that I had done, I had believed that O_DIRECT ought to be faster than not using O_DIRECT because it was more “direct” i.e. bypasses the page cache. I found some supporting evidence by running fio with and without O_DIRECT. On my old system, when I ran:
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
It gave 3.5GB/s
But when I ran
fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=0 --numjobs=1 --runtime=60 --group_reporting
It gave only 2.3GB/s
So O_DIRECT made fio faster on my older system.
On my current system, I get similar results:
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=1 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=32
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][-.-%][r=3364MiB/s][r=3364 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=3178: Tue Jul 25 00:15:53 2023
read: IOPS=3277, BW=3278MiB/s (3437MB/s)(10.0GiB/3124msec)
slat (usec): min=6, max=315, avg=18.13, stdev= 8.69
clat (usec): min=570, max=22048, avg=9463.51, stdev=1283.30
lat (usec): min=601, max=22075, avg=9481.64, stdev=1282.47
clat percentiles (usec):
| 1.00th=[ 6783], 5.00th=[ 9110], 10.00th=[ 9110], 20.00th=[ 9110],
| 30.00th=[ 9110], 40.00th=[ 9241], 50.00th=[ 9241], 60.00th=[ 9503],
| 70.00th=[ 9634], 80.00th=[ 9634], 90.00th=[ 9634], 95.00th=[ 9896],
| 99.00th=[16319], 99.50th=[19268], 99.90th=[21627], 99.95th=[21890],
| 99.99th=[22152]
bw ( MiB/s): min= 2786, max= 3412, per=99.98%, avg=3277.33, stdev=241.55, samples=6
iops : min= 2786, max= 3412, avg=3277.33, stdev=241.55, samples=6
lat (usec) : 750=0.04%, 1000=0.04%
lat (msec) : 2=0.16%, 4=0.30%, 10=95.47%, 20=3.60%, 50=0.39%
cpu : usr=0.42%, sys=10.53%, ctx=10238, majf=0, minf=536
IO depths : 1=0.1%, 2=0.1%, 4=0.2%, 8=0.4%, 16=0.8%, 32=98.5%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=3278MiB/s (3437MB/s), 3278MiB/s-3278MiB/s (3437MB/s-3437MB/s), io=10.0GiB (10.7GB), run=3124-3124msec
Disk stats (read/write):
nvme0n1: ios=37911/0, merge=0/0, ticks=350894/0, in_queue=350893, util=93.96%
$ fio --name TEST --eta-newline=5s --filename=temp.file --rw=read --size=2g --io_size=10g --blocksize=1024k --ioengine=io_uring --fsync=10000 --iodepth=32 --direct=0 --numjobs=1 --runtime=60 --group_reporting
TEST: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=io_uring, iodepth=32
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [R(1)][80.0%][r=2048MiB/s][r=2048 IOPS][eta 00m:01s]
TEST: (groupid=0, jobs=1): err= 0: pid=3198: Tue Jul 25 00:16:40 2023
read: IOPS=2104, BW=2104MiB/s (2207MB/s)(10.0GiB/4866msec)
slat (usec): min=28, max=5133, avg=134.55, stdev=233.41
clat (usec): min=4680, max=31030, avg=13921.79, stdev=1822.86
lat (usec): min=5963, max=31226, avg=14056.34, stdev=1782.46
clat percentiles (usec):
| 1.00th=[ 7767], 5.00th=[11469], 10.00th=[13042], 20.00th=[13435],
| 30.00th=[13698], 40.00th=[13829], 50.00th=[13960], 60.00th=[14091],
| 70.00th=[14222], 80.00th=[14484], 90.00th=[14746], 95.00th=[15008],
| 99.00th=[21890], 99.50th=[24773], 99.90th=[29230], 99.95th=[29492],
| 99.99th=[30016]
bw ( MiB/s): min= 1820, max= 2328, per=99.54%, avg=2094.67, stdev=246.01, samples=9
iops : min= 1820, max= 2328, avg=2094.67, stdev=246.01, samples=9
lat (msec) : 10=2.64%, 20=95.90%, 50=1.46%
cpu : usr=0.06%, sys=91.00%, ctx=17435, majf=0, minf=536
IO depths : 1=0.1%, 2=0.1%, 4=0.2%, 8=0.4%, 16=0.8%, 32=98.5%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=2104MiB/s (2207MB/s), 2104MiB/s-2104MiB/s (2207MB/s-2207MB/s), io=10.0GiB (10.7GB), run=4866-4866msec
Disk stats (read/write):
nvme0n1: ios=39042/0, merge=0/0, ticks=165950/0, in_queue=165950, util=91.21%
So, I think O_DIRECT is probably necessary to reach the maximal performance, but it is definitely very sensitive to the block size. I remember when I first started with O_DIRECT I was using the same small block size (64KiB) for both O_DIRECT and non-O_DIRECT I was seeing that O_DIRECT made my program slower. Since O_DIRECT performance is heavily affected by the block size, choosing a bad block size will result in terrible performance from O_DIRECT, but I have found that the best possible performance is obtainable only with O_DIRECT - you can check this for yourself since I made whether or not to use O_DIRECT a command line argument in my program too so you can easily compare the performance with and without it for different block sizes.
At the start, I was using a block size of 64KiB, and I did not expect block size to make that much of a difference, so I was initially quite disappointed by the O_DIRECT performance, which was much worse than the non-O_DIRECT performance before I started changing the block size . Anyway, so I decided to see whether the BLOCK SIZE (BS) and the QUEUE DEPTH (QD) affected performance, and found that the optimal combinations of BS and QD were BS=256, QD=8 for non-O_DIRECT while for O_DIRECT the optimal combination was BS=4096, QD=8.
Table:
| Buffer Size (in KB) | Queue Depth | O_DIRECT | call process in loop | Running Time (s) |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 7.134 |
| 1 | 1 | 1 | 0 | 29.881 |
| 1 | 4000 | 0 | 0 | 3.647 |
| 1 | 4000 | 1 | 0 | 29.624 |
| 1 | 4000 | 0 | 1 | 3.619 |
| 1 | 4000 | 1 | 1 | 22.177 |
| 4 | 1 | 0 | 1 | 2.732 |
| 4 | 1 | 1 | 1 | 9.972 |
| 4 | 64 | 0 | 1 | 1.665 |
| 4 | 64 | 1 | 1 | 4.423 |
| 4 | 4000 | 0 | 0 | 1.591 |
| 4 | 4000 | 1 | 0 | 6.452 |
| 4 | 4000 | 0 | 1 | 1.572 |
| 4 | 4000 | 1 | 1 | 6.468 |
| 16 | 1 | 0 | 1 | 1.16 |
| 16 | 1 | 1 | 1 | 4.88 |
| 16 | 64 | 0 | 1 | 1.051 |
| 16 | 64 | 1 | 1 | 1.816 |
| 64 | 1 | 0 | 1 | 0.829 |
| 64 | 1 | 1 | 1 | 3.122 |
| 64 | 2 | 0 | 0 | 1.144 |
| 64 | 2 | 1 | 0 | 1.464 |
| 64 | 4 | 0 | 0 | 0.542 |
| 64 | 4 | 1 | 0 | 0.489 |
| 64 | 8 | 0 | 0 | 0.422 |
| 64 | 8 | 1 | 0 | 0.371 - 0.602 |
| 64 | 8 | 0 | 1 | 0.611 |
| 64 | 8 | 1 | 1 | 0.795 |
| 64 | 16 | 0 | 0 | 0.429 |
| 64 | 16 | 1 | 0 | 0.358 - 0.645 |
| 64 | 16 | 0 | 1 | 0.613 |
| 64 | 16 | 1 | 1 | 0.793 |
| 64 | 32 | 0 | 0 | 0.479 |
| 64 | 32 | 1 | 0 | 0.374 - 0.533 |
| 64 | 64 | 0 | 1 | 0.645 |
| 64 | 64 | 1 | 1 | 0.783 |
| 64 | 4000 | 0 | 0 | 0.388 |
| 64 | 4000 | 1 | 0 | 0.837 |
| 64 | 4000 | 0 | 1 | 0.37 |
| 64 | 4000 | 1 | 1 | 0.877 |
| 128 | 4 | 0 | 0 | 0.494 |
| 128 | 8 | 0 | 0 | 0.324 - 0.373 |
| 128 | 16 | 0 | 0 | 0.333 - 0.359 |
| 256 | 4 | 0 | 0 | 0.415 - 0.442 |
| 256 | 8 | 0 | 0 | 0.322 - 0.359 |
| 256 | 16 | 0 | 0 | 0.322 - 0.343 |
| 256 | 32 | 0 | 0 | 0.331 - 0.351 |
| 256 | 32 | 0 | 1 | 0.405 - 0.428 |
| 512 | 2 | 0 | 0 | 0.832 |
| 512 | 2 | 1 | 0 | 1.295 |
| 512 | 2 | 0 | 1 | 0.894 |
| 512 | 2 | 1 | 1 | 0.748 - 1.383 |
| 512 | 4 | 0 | 0 | 0.51 |
| 512 | 4 | 1 | 0 | 0.321 - 0.349 |
| 512 | 8 | 0 | 0 | 0.4 |
| 512 | 8 | 1 | 0 | 0.320 - 0.355 |
| 512 | 16 | 0 | 0 | 0.397 |
| 512 | 16 | 1 | 0 | 0.320 - 0.337 |
| 512 | 32 | 0 | 0 | 0.398 |
| 512 | 32 | 1 | 0 | 0.319 - 0.334 |
| 512 | 64 | 0 | 0 | 0.398 |
| 512 | 64 | 1 | 0 | 0.325-0.388 |
| 512 | 128 | 0 | 0 | 0.399 |
| 512 | 128 | 1 | 0 | 0.409 |
| 512 | 256 | 0 | 0 | 0.4 |
| 512 | 4000 | 0 | 0 | 0.406 |
| 1024 | 4 | 0 | 0 | 0.442 |
| 1024 | 4 | 1 | 0 | 0.339 - 0.343 |
| 1024 | 8 | 0 | 0 | 0.399 |
| 1024 | 8 | 1 | 0 | 0.320 - 0.321 |
| 1024 | 16 | 0 | 0 | 0.398 |
| 1024 | 16 | 1 | 0 | 0.319 - 0.358 |
| 1024 | 32 | 0 | 0 | 0.4 |
| 1024 | 32 | 1 | 0 | 0.319 - 0.373 |
| 1024 | 64 | 0 | 0 | 0.402 |
| 1024 | 64 | 1 | 0 | 0.320 - 0.443 |
| 1024 | 128 | 0 | 0 | 0.404 |
| 1024 | 128 | 1 | 0 | 0.45 |
| 1024 | 128 | 0 | 1 | 0.406 |
| 1024 | 128 | 1 | 1 | 0.477 |
| 2048 | 4 | 0 | 0 | 0.424 |
| 2048 | 4 | 1 | 0 | 0.341 - 0.361 |
| 2048 | 8 | 0 | 0 | 0.4 |
| 2048 | 8 | 1 | 0 | 0.319 - 0.336 |
| 2048 | 16 | 0 | 0 | 0.4 |
| 2048 | 16 | 1 | 0 | 0.329 - 0.372 |
| 2048 | 32 | 0 | 0 | 0.404 |
| 2048 | 32 | 1 | 0 | 0.402 - 0.410 |
| 4096 | 4 | 0 | 0 | 0.415 |
| 4096 | 4 | 1 | 0 | 0.383 - 0.525 |
| 4096 | 4 | 0 | 1 | 0.644 |
| 4096 | 4 | 1 | 1 | 0.71 |
| 4096 | 8 | 0 | 0 | 0.388 |
| 4096 | 8 | 1 | 0 | 0.309 - 0.343 |
| 4096 | 8 | 1 | 1 | 0.425 - 0.506 |
| 4096 | 16 | 0 | 0 | 0.398 |
| 4096 | 16 | 1 | 0 | 0.318 - 0.356 |
| 4096 | 16 | 0 | 1 | 0.498 |
| 4096 | 16 | 1 | 1 | 0.364 |
| 4096 | 32 | 0 | 0 | 0.402 |
| 4096 | 32 | 1 | 0 | 0.362 - 0.379 |
| 4096 | 64 | 0 | 0 | 0.418 |
| 4096 | 64 | 1 | 0 | 0.388 |
| 8192 | 4 | 0 | 0 | 0.416 |
| 8192 | 4 | 1 | 0 | 0.342 - 0.429 |
| 8192 | 8 | 0 | 0 | 0.387 |
| 8192 | 8 | 1 | 0 | 0.308 - 0.345 |
| 8192 | 8 | 1 | 1 | 0.414 - 0.464 |
| 8192 | 16 | 0 | 0 | 0.4 |
| 8192 | 16 | 1 | 0 | 0.333 - 0.348 |
| 8192 | 32 | 0 | 0 | 0.428 |
| 8192 | 32 | 1 | 0 | 0.351 |
| 8192 | 64 | 0 | 0 | 0.427 |
| 8192 | 64 | 1 | 0 | 0.4 |
| 16384 | 4 | 0 | 0 | 0.42 |
| 16384 | 4 | 1 | 0 | 0.329 - 0.367 |
| 16384 | 8 | 0 | 0 | 0.401 |
| 16384 | 8 | 1 | 0 | 0.327 - 0.338 |
| 16384 | 16 | 0 | 0 | 0.424 |
| 16384 | 16 | 1 | 0 | 0.333 - 0.360 |
| 16384 | 32 | 0 | 0 | 0.434 |
| 16384 | 32 | 1 | 0 | 0.361 - 0.390 |
The above results are for an old version of my program that was doing a malloc (or 2) for every read request and not using a ring buffer.
The interaction between malloc, free, and O_DIRECT
My liburing b3sum program is a modified version of the original liburing cp program, and the original liburing cp program did a malloc for each read request (allocating the buffer for each request), so that’s what my program did originally. The earlier versions of my liburing b3sum program were issuing requests for 64KiB chunks at a time, which meant a lot of mallocs when reading a 1GiB file, and was not using O_DIRECT, and I noticed that calling free on the blocks when I’m finished with them sped up my program from around 0.339s-0.348s to 0.322s-0.332s, a hugely noticeable and significant speedup.
After I found the optimal block sizes for O_DIRECT and nonO_DIRECT, I tried usingfree again to see if that made a difference. And I found that after uncommenting the free() in my code:
The O_DIRECT version (8192 8 1 0) went from 0.307-0.342s to 0.330-0.355s
The non-O_DIRECT version (256 8 0 0) went from 0.322-0.345s to 0.306-0.327s
So now the non-O_DIRECT version was faster again! I’m not sure why calling free slows down the O_DIRECT version but speeds up the non-O_DIRECT version of my program. I mean, it makes sense that it speeds up the non-O_DIRECT version, the idea is that the call to free() doesn’t actually return the memory back to the system but rather marks it for use by my program so that future calls of malloc simply just reuse the same pieces of memory instead of actually asking the kernel for more memory. Actually, in the process of switching from readv to read I added a second malloc in the function for creating a read request, which increased the program’s running time from around 0.333s to around 0.340s - at the time I thought it was because read was slower than readv, but now I think it’s probably due to the extra malloc. As an aside, one of the surprising things for me when switching from readv to read was that the io_uring read (unlike the regular read) takes an offset, so it’s actually more like pread rather than the regular read syscall (which doesn’t take an offset).
Anyways, so I decided cut down the number of mallocs in my program down to just 2 at startup. Now I was allocating all of the buffers in a single malloc at the start, and now I was getting 0.297s for the O_DIRECT version and 0.363s for the non-O_DIRECT. So allocating all memory at the start sped up the O_DIRECT version by around 0.01 seconds while it slowed down the non-O_DIRECT version by around 0.057 seconds! I also tried busy-polling (using atomics) instead of condition variables and that didn’t make any difference to the running time. btw, yes, 0.297s is lower than any of the numbers that I’m getting on my current system, but then again fio was also faster on my old system too - I suspect it’s because I was using LVM and that somehow made my file system faster.
hdparm results
hdparm on my current system:
$ hdparm --direct -t -T /dev/nvme0n1
/dev/nvme0n1:
Timing O_DIRECT cached reads: 2478 MB in 2.00 seconds = 1238.85 MB/sec
Timing O_DIRECT disk reads: 7970 MB in 3.00 seconds = 2656.42 MB/sec
$ hdparm --direct -t -T /dev/nvme0n1
/dev/nvme0n1:
Timing O_DIRECT cached reads: 3400 MB in 2.00 seconds = 1700.47 MB/sec
Timing O_DIRECT disk reads: 9816 MB in 3.00 seconds = 3271.78 MB/sec
$ hdparm --direct -t -T /dev/nvme0n1
/dev/nvme0n1:
Timing O_DIRECT cached reads: 3380 MB in 2.00 seconds = 1690.65 MB/sec
Timing O_DIRECT disk reads: 9834 MB in 3.00 seconds = 3277.73 MB/sec
hdparm on my previous system (using LVM encryption):
$ hdparm --direct -t -T /dev/nvme0n1p3
/dev/nvme0n1p3:
Timing O_DIRECT cached reads: 3510 MB in 2.00 seconds = 1755.66 MB/sec
Timing O_DIRECT disk reads: 9026 MB in 3.00 seconds = 3008.23 MB/sec
hdparm consistently gives much lower readings than fio, which reported 3.5GB/s using io_uring, libaio and POSIX aio. That might be due to the fact that hdparm just uses the normal synchronous read(). Here’s the source code:
static int read_big_block (int fd, char *buf)
{
int i, rc;
if ((rc = read(fd, buf, TIMING_BUF_BYTES)) != TIMING_BUF_BYTES) {
if (rc) {
if (rc == -1)
perror("read() failed");
else
fprintf(stderr, "read(%u) returned %u bytes\n", TIMING_BUF_BYTES, rc);
} else {
fputs ("read() hit EOF - device too small\n", stderr);
}
return 1;
}
/* access all sectors of buf to ensure the read fully completed */
for (i = 0; i < TIMING_BUF_BYTES; i += 512)
buf[i] &= 1;
return 0;
}
Is dd really making read() syscalls?
I guess I need to prove that dd really is doing read syscalls with bs size, so let me show you the ltrace log produced by this command: echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ltrace -S -o ltrace1.out dd if=1GB.txt bs=64K | ltrace -S -o ltrace2.out ./example_64K
$ head -150 ltrace1.out
SYS_brk(0) = 0x56024ac4f000
SYS_mmap(0, 8192, 3, 34) = 0x7fed83534000
SYS_access("/etc/ld.so.preload", 04) = -2
SYS_openat(0xffffff9c, 0x7fed8355e0b1, 0x80000, 0) = 3
SYS_newfstatat(3, 0x7fed8355ec99, 0x7ffe6f8fd8a0, 4096) = 0
SYS_mmap(0, 0x63b6, 1, 2) = 0x7fed8352d000
SYS_close(3) = 0
SYS_openat(0xffffff9c, 0x7fed83534140, 0x80000, 0) = 3
SYS_read(3, "\177ELF\002\001\001\003", 832) = 832
SYS_pread(3, 0x7ffe6f8fd620, 784, 64) = 784
SYS_newfstatat(3, 0x7fed8355ec99, 0x7ffe6f8fd8a0, 4096) = 0
SYS_pread(3, 0x7ffe6f8fd4f0, 784, 64) = 784
SYS_mmap(0, 0x1e0f50, 1, 2050) = 0x7fed8334c000
SYS_mmap(0x7fed83372000, 0x155000, 5, 2066) = 0x7fed83372000
SYS_mmap(0x7fed834c7000, 0x53000, 1, 2066) = 0x7fed834c7000
SYS_mmap(0x7fed8351a000, 0x6000, 3, 2066) = 0x7fed8351a000
SYS_mmap(0x7fed83520000, 0xcf50, 3, 50) = 0x7fed83520000
SYS_close(3) = 0
SYS_mmap(0, 0x3000, 3, 34) = 0x7fed83349000
SYS_arch_prctl(4098, 0x7fed83349740, 0xffff80127ccb5f30, 34) = 0
SYS_set_tid_address(0x7fed83349a10, 0x7fed83349740, 0x7fed835690d0, 34) = 0x701f0
SYS_set_robust_list(0x7fed83349a20, 24, 0x7fed835690d0, 34) = 0
SYS_334(0x7fed8334a060, 32, 0, 0x53053053) = 0
SYS_mprotect(0x7fed8351a000, 16384, 1) = 0
SYS_mprotect(0x56024a719000, 4096, 1) = 0
SYS_mprotect(0x7fed83566000, 8192, 1) = 0
SYS_prlimit64(0, 3, 0, 0x7ffe6f8fe3e0) = 0
SYS_munmap(0x7fed8352d000, 25526) = 0
getenv("POSIXLY_CORRECT") = nil
sigemptyset(<>) = 0
sigaddset(<9>, SIGUSR1) = 0
sigaction(SIGINT, nil <unfinished ...>
SYS_rt_sigaction(2, 0, 0x7ffe6f8fe4c0, 8) = 0
<... sigaction resumed> , { 0, <>, 0x5f004554, 0x5f796c7261655f63 }) = 0
sigaddset(<1,9>, SIGINT) = 0
sigismember(<1,9>, SIGUSR1) = 1
sigaction(SIGUSR1, { 0x56024a7086b0, <1,9>, 0, 0 } <unfinished ...>
SYS_rt_sigaction(10, 0x7ffe6f8fe420, 0, 8) = 0
<... sigaction resumed> , nil) = 0
sigismember(<1,9>, SIGINT) = 1
sigaction(SIGINT, { 0x56024a7086a0, <1,9>, 0, 0 } <unfinished ...>
SYS_rt_sigaction(2, 0x7ffe6f8fe420, 0, 8) = 0
<... sigaction resumed> , nil) = 0
strrchr("dd", '/') = nil
setlocale(LC_ALL, "" <unfinished ...>
SYS_318(0x7fed83525478, 8, 1, 0x7fed83361e40) = 8
SYS_brk(0) = 0x56024ac4f000
SYS_brk(0x56024ac70000) = 0x56024ac70000
SYS_openat(0xffffff9c, 0x7fed834eaf50, 0x80000, 0) = 3
SYS_newfstatat(3, 0x7fed834e1dd5, 0x7fed8351fb60, 4096) = 0
SYS_mmap(0, 0x2e8610, 1, 2) = 0x7fed83000000
SYS_close(3) = 0
<... setlocale resumed> ) = "en_GB.UTF-8"
bindtextdomain("coreutils", "/usr/share/locale") = "/usr/share/locale"
textdomain("coreutils") = "coreutils"
__cxa_atexit(0x56024a708a20, 0, 0x56024a71a268, 0) = 0
getpagesize() = 4096
getopt_long(3, 0x7ffe6f8fe7c8, "", 0x56024a719d20, nil) = -1
strchr("if=1GB.txt", '=') = "=1GB.txt"
strchr("bs=64K", '=') = "=64K"
__errno_location() = 0x7fed833496c0
__ctype_b_loc() = 0x7fed833496d8
strtoumax(0x7ffe6f8ffda0, 0x7ffe6f8fe5d0, 10, 0x7fed8301982c) = 64
strchr("bcEGkKMPTwYZ0", 'K') = "KMPTwYZ0"
strchr("bcEGkKMPTwYZ0", '0') = "0"
strchr("64K", 'B') = nil
open("1GB.txt", 0, 00 <unfinished ...>
SYS_openat(0xffffff9c, 0x7ffe6f8ffd95, 0, 0) = 3
<... open resumed> ) = 3
dup2(3, 0 <unfinished ...>
SYS_dup2(3, 0) = 0
<... dup2 resumed> ) = 0
__errno_location() = 0x7fed833496c0
close(3 <unfinished ...>
SYS_close(3) = 0
<... close resumed> ) = 0
lseek(0, 0, 1 <unfinished ...>
SYS_lseek(0, 0, 1) = 0
<... lseek resumed> ) = 0
__errno_location() = 0x7fed833496c0
dcgettext(0, 0x56024a715475, 5, 0x7fed83444177 <unfinished ...>
SYS_openat(0xffffff9c, 0x7ffe6f8fe0d0, 0x80000, 0) = 3
SYS_newfstatat(3, 0x7fed834e1dd5, 0x7ffe6f8fdf00, 4096) = 0
SYS_read(3, "# Locale name alias data base.\n#"..., 4096) = 2996
SYS_read(3, "", 4096) = 0
SYS_close(3) = 0
SYS_openat(0xffffff9c, 0x56024ac50410, 0, 0) = -2
SYS_openat(0xffffff9c, 0x56024ac50670, 0, 0) = -2
<... dcgettext resumed> ) = 0x56024a715475
clock_gettime(1, 0x7ffe6f8fe540, 0x56024a715475, 0x56024a715475) = 0
aligned_alloc(4096, 0x10000, 0, 24) = 0x56024ac53000
read(0 <unfinished ...>
SYS_read(0, "\277\377#IX0=\251\353\201\343v\345(\221\032I\253\333\v2#\370J\304\352\300\342\016(\006\255"..., 65536) = 65536
<... read resumed> , "\277\377#IX0=\251\353\201\343v\345(\221\032I\253\333\v2#\370J\304\352\300\342\016(\006\255"..., 65536) = 65536
write(1, "\277\377#IX0=\251\353\201\343v\345(\221\032I\253\333\v2#\370J\304\352\300\342\016(\006\255"..., 65536 <unfinished ...>
SYS_write(1, "\277\377#IX0=\251\353\201\343v\345(\221\032I\253\333\v2#\370J\304\352\300\342\016(\006\255"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "y]mq\351\312\36167\341\023\336\220e\242\265G\020VY]\352\022Z/\241-C\357\270K\237"..., 65536) = 65536
<... read resumed> , "y]mq\351\312\36167\341\023\336\220e\242\265G\020VY]\352\022Z/\241-C\357\270K\237"..., 65536) = 65536
write(1, "y]mq\351\312\36167\341\023\336\220e\242\265G\020VY]\352\022Z/\241-C\357\270K\237"..., 65536 <unfinished ...>
SYS_write(1, "y]mq\351\312\36167\341\023\336\220e\242\265G\020VY]\352\022Z/\241-C\357\270K\237"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "\230\322GS\223", 65536) = 65536
<... read resumed> , "\230\322GS\223", 65536) = 65536
write(1, "\230\322GS\223", 65536 <unfinished ...>
SYS_write(1, "\230\322GS\223", 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "\251\252-\322p\365\3644\237\333\272\024\335\226\262\337\353\263+a\305\224Bg2\357]U\240G\2625"..., 65536) = 65536
<... read resumed> , "\251\252-\322p\365\3644\237\333\272\024\335\226\262\337\353\263+a\305\224Bg2\357]U\240G\2625"..., 65536) = 65536
write(1, "\251\252-\322p\365\3644\237\333\272\024\335\226\262\337\353\263+a\305\224Bg2\357]U\240G\2625"..., 65536 <unfinished ...>
SYS_write(1, "\251\252-\322p\365\3644\237\333\272\024\335\226\262\337\353\263+a\305\224Bg2\357]U\240G\2625"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "\330K\253,\3775\362\272\206\213>\272\217\233\234\027\367\372Q\342Y\223c\234\301\241r\311\362\237\001V"..., 65536) = 65536
<... read resumed> , "\330K\253,\3775\362\272\206\213>\272\217\233\234\027\367\372Q\342Y\223c\234\301\241r\311\362\237\001V"..., 65536) = 65536
write(1, "\330K\253,\3775\362\272\206\213>\272\217\233\234\027\367\372Q\342Y\223c\234\301\241r\311\362\237\001V"..., 65536 <unfinished ...>
SYS_write(1, "\330K\253,\3775\362\272\206\213>\272\217\233\234\027\367\372Q\342Y\223c\234\301\241r\311\362\237\001V"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "*WG\314\356\253\230\0319\256E\004\022\214\343", 65536) = 65536
<... read resumed> , "*WG\314\356\253\230\0319\256E\004\022\214\343", 65536) = 65536
write(1, "*WG\314\356\253\230\0319\256E\004\022\214\343", 65536 <unfinished ...>
SYS_write(1, "*WG\314\356\253\230\0319\256E\004\022\214\343", 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "EU\230\b\306", 65536) = 65536
<... read resumed> , "EU\230\b\306", 65536) = 65536
write(1, "EU\230\b\306", 65536 <unfinished ...>
SYS_write(1, "EU\230\b\306", 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "Q\366\034&\357\020\0371Ln\254\347\202\260Q\254\343\242\203\254f\375\2164\022\376\253FJ\320W\262"..., 65536) = 65536
<... read resumed> , "Q\366\034&\357\020\0371Ln\254\347\202\260Q\254\343\242\203\254f\375\2164\022\376\253FJ\320W\262"..., 65536) = 65536
write(1, "Q\366\034&\357\020\0371Ln\254\347\202\260Q\254\343\242\203\254f\375\2164\022\376\253FJ\320W\262"..., 65536 <unfinished ...>
SYS_write(1, "Q\366\034&\357\020\0371Ln\254\347\202\260Q\254\343\242\203\254f\375\2164\022\376\253FJ\320W\262"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "}n\t7\226\001\306Q\3029}\3408l!\351\026\177F\037x\237BQ\2242\215\030\021\342\364F"..., 65536) = 65536
<... read resumed> , "}n\t7\226\001\306Q\3029}\3408l!\351\026\177F\037x\237BQ\2242\215\030\021\342\364F"..., 65536) = 65536
write(1, "}n\t7\226\001\306Q\3029}\3408l!\351\026\177F\037x\237BQ\2242\215\030\021\342\364F"..., 65536 <unfinished ...>
SYS_write(1, "}n\t7\226\001\306Q\3029}\3408l!\351\026\177F\037x\237BQ\2242\215\030\021\342\364F"..., 65536) = 65536
<... write resumed> ) = 65536
read(0 <unfinished ...>
SYS_read(0, "\rx\213\343\021\213M\243\345Vl\304+G6J\250\202\372\266`k\354W\364>\233\337Q\323\037\253"..., 65536) = 65536
<... read resumed> , "\rx\213\343\021\213M\243\345Vl\304+G6J\250\202\372\266`k\354W\364>\233\337Q\323\037\253"..., 65536) = 65536
write(1, "\rx\213\343\021\213M\243\345Vl\304+G6J\250\202\372\266`k\354W\364>\233\337Q\323\037\253"..., 65536 <unfinished ...>
SYS_write(1, "\rx\213\343\021\213M\243\345Vl\304+G6J\250\202\372\266`k\354W\364>\233\337Q\323\037\253"..., 65536) = 65536
See? There’s no funny business going on here - dd really is making all those SYS_read syscalls, asking for 64KiB at a time and then writing those 64KiB out. And I also verified that when you use bs=2M, dd will ask for 2M at a time. I looked at cat as well, for good measure: echo 1 > /proc/sys/vm/drop_caches; sleep 1; time ltrace -S -o ltrace1.out cat 1GB.txt | ltrace -S -o ltrace2.out ./example_64K and found that, as expected, cat is reading the file in 128KiB at a time and writing it out. It really is making those read() syscalls (the SYS_read) with 128KiB as the parameter. Anyway, I thought it was interesting that when using dd to pipe data into my program, a bs of 64KiB was optimal, but when using dd to pipe data into /dev/null, a larger bs of 2M was optimal. It is also interesting to note that cat was able to pipe data into /dev/null at the maximum possible speed, despite using a 128KiB buffer size (when I used dd with bs=128KiB, it could not reach the max speed…).
Motivation
So why did I write this program? Well, a few years ago I was running my own MediaWiki instance and had some problems with it (e.g. database fails to start with some error, search engine just one day stopped indexing new pages, renaming pages causes link rot, etc.) so I decided to write my own wiki, and I thought: “well, if I’m going to write own my wiki, I should write a backup tool for my wiki too” so I decided to write a backup tool and then I thought “but what if the backup gets corrupted” so I decided to include forward error correction (ECC) with my backups and that’s when I looked at par2cmdline and noticed that it’s quite slow so I decided to write my own ECC tool so then I started reading the PAR3 specification and saw that it used the BLAKE3 hash. So I then started looked at hashing algorithms, and I saw that most of the non-cryptographic hashing algorithms (e.g. xxhash) have no guarantees on collision probability, actually I think most of the non-cryptographic hashing algorithms are designed to be used in hash tables where collisions can be detected and resolved, rather than for detecting file corruption where there is no way of even knowing whether a collision happened. Granted, the probability of a corrupted file having the same hash as the original file is small, but I wanted to make that probability truly negligible so that I don’t have to worry about it. So I began to look at the cryptographic hashes - md5, sha1, sha2, sha3 and so on, and I found BLAKE3 to be the fastest single-thread cryptographic hash that I could find (yes, BLAKE3 is even faster than the openssl implementations of SHA1 and SHA2 on my AMD64 system even though my system has sha_ni but no AVX512 - only AVX2 😭😭😭) plus it was parallelizable unlike the other hashes so I decided to go with BLAKE3. Anyway so I started implementing my own ECC tool and the first step was to compute a hash of the file. And that’s why I created this program.